
NLTK - mi primer Tutorial
4 Ene 2017 16 mins 5 Ene 2017Hay muchos tutoriales y ejemplos del uso de esta fantástica librería, lamentablemente casi todo está orientado a la lengua inglesa. Vamos a tratar de ir desarrollando el contenido de este tutorial orientado al español.
Análisis de texto básico
Hay algunas funciones elementales de análisis muy interesantes que podremos hacer con NLTK, para empezar lo que se necesitará obviamente es el texto que se quiere analizar. Una forma sencilla y que se repite en cientos de tutoriales, es la de descargarse los ejemplos del libro de la NLTK, mucha funcionalidad va a requerir descargarse distintos “corpus” o “modelos”, estos paquetes se necesitan para distintas funcionalidades de la librería, algunos como “Panles lite Corpus” pueden ocupar varios Gbytes. Los ejemplos del libro oficial de NLTK se agrupan en la colección “Book” y ofrece cosas como “Moby Dick”, los discursos inaugurales de los presidentes norteamericanos, etc.
Para descargar “corpus” o “modelos”
import nltk
nltk.download()
Hay que seleccionar el “corpus” Book, tengan en cuenta que si todo está correctamente instalado, debiera abrirse un ventana gráfica (Si se cuenta con TKinter/Tcl) o bien la selección se haría en modo texto.
Nota: la mejor definición de lo que es un “corpus” la ofrece la wikipedia: Un corpus lingüístico es un conjunto amplio y estructurado de ejemplos reales de uso de la lengua
Trabajando con los ejemplos
Lo primero es importar los textos, esto creara unas variables text<n>, cada una contiene el contenido completo del libro
from nltk.book import *
text1
<Text: Moby Dick by Herman Melville 1851>
Conceptualmente, un objeto nltk.text no es más que una lista ordenada de tokens, siendo esto la unidad mínima de un texto, simplemente palabras o signos de puntuación. Esto podemos verlo fácilmente de la siguiente manera
text1[0:9] # hacemos un "slice" de los primeros 10 tokens
['[', 'Moby', 'Dick', 'by', 'Herman', 'Melville', '1851', ']', 'ETYMOLOGY', '.']
Si revisáramos el texto en la carpeta nltk_data/corpora/gutemberg, veríamos en el caso del archivo de “Moby Dick” que justamente comienza de la siguiente forma:
[Moby Dick by Herman Melville 1851]
ETYMOLOGY.
Vemos entonces que “tokenización” que se hizo hace algunas cosas interesantes y para nada triviales:
- Separa convenientemente signos de puntuación y palabras
- Elimina caracteres en blanco y saltos de línea
Trabajando con nuestros propios textos
Vamos a empezar a trabajar sobre nuestros propios ejemplos, la idea es crear un nltk.text desde el principio y aprovecharlo para ir mostrando las funcionalidades elementales de análisis. Para empezar debemos contar con un “texto”, que puede ser cualquier cosa: un mail, un libro, una nota, un twit, un chat, etc. Lo importante es partir de un “texto” claro. Lo que voy a hacer es importar directamente del Proyecto Gutemberg, un libro que nos hacían leer, al menos en mi época, en la secundaria, se trata de Juvenilia.
from urllib import request
"""
Descarga de un texto
"""
url = "http://www.gutenberg.org/cache/epub/41575/pg41575.txt"
response = request.urlopen(url)
raw = response.read().decode('utf8')
print(type(raw))
print(len(raw))
print(raw[:75])
(*) El ejemplo descarga directamente un documento, pero se ve claro que lo que necesitamos en principio es una cadena de texto, por lo que se entiende que tranquilamente podemos leer el archivo, recuperarlo de una base de datos, etc.
La salida:
<class 'str'>
532748
The Project Gutenberg EBook of Juvenilla; Prosa ligera, by Miguel Cané
Como primer paso hay que “tokenizar” el texto de la siguiente forma:
"""
Tokenización del texto
"""
from nltk import word_tokenize
tokens = word_tokenize(raw)
print(type(tokens))
print(len(tokens))
print(tokens[:10])
La salida:
<class 'list'>
101103
['\ufeffThe', 'Project', 'Gutenberg', 'EBook', 'of', 'Juvenilla', ';', 'Prosa', 'ligera', ',']
Lo interesante que la rutina word_tokenize de nltk transformo una larga cadena de caracteres en una lista de tokens, lo siguiente es convertir esta lista en un nltk.text:
text = nltk.Text(tokens)
print(type(tokens))
print(len(tokens))
print(tokens[:10])
La salida:
<class 'list'>
101103
['\ufeffThe', 'Project', 'Gutenberg', 'EBook', 'of', 'Juvenilla', ';', 'Prosa', 'ligera', ',']
Ya conformada la variable nltk.text podemos empezar a hacer varios análisis interesantes
Búsqueda de patrones.
text.findall("<un>(<.*>)<especial>")
sabor; subjetivismo; aparato; momento; sentimiento; orden; acento;
problema
Buscar con contexto.
Un análisis muy interesante que podemos hacer sobre un texto, es mediante el uso de concordance, esta función nos permite buscar una determinada palabra y analizar su contexto. Por ejemplo:
text.concordance("Sarmiento")
Displaying 25 of 78 matches:
zación nacional . Contemporáneo de Sarmiento , Vicente F. López y Alberdi , per
o de nuestros escritores de nota . Sarmiento era demasiado impetuoso para mante
en la escena política de su país . Sarmiento en París Salgo del taller de Rodin
del taller de Rodin ; la figura de Sarmiento va tomando vida y forma . El sober
asado el síncope [ 20 ] y de nuevo Sarmiento surge en mi memoria , como si su p
z tomos publicados de las obras de Sarmiento [ 21 ] , haced un esfuerzo sobre v
as comparables a algunas de las de Sarmiento en sus _Viajes_ , al retrato de do
ágina que no haya sido escrita por Sarmiento ; hay muy poco inédito , porque pa
hay muy poco inédito , porque para Sarmiento , escribir era obrar . Así , en es
ón dolorosa de una profanación . I Sarmiento se embarca , pues , sobre la _Enri
n , a don Bernardino Rivadavia ... Sarmiento descubre , al pasar , la isla de R
ltimos años de vigor intelectual . Sarmiento pasa rápidamente por Montevideo ,
llo de nobleza de ese abolengo ... Sarmiento venía de Chile , a donde los últim
o de Janeiro , en rumbo a Europa , Sarmiento debió sacudir su poderosa cabeza ,
is , conocéis el estilo general de Sarmiento , ese ímpetu un tanto desordenado
l» las pruebas de los artículos de Sarmiento . Allí se topa también con el _par
, pero que él se había resistido . Sarmiento le toma el pelo en el acto y deplo
ero confortable ... II Al fin pisa Sarmiento tierra de Europa , remonta el Sena
tuve el honor de ser compañero de Sarmiento en el Consejo General de Educación
La primera impresión de París que Sarmiento comunica a Aberastain es caracterí
Romeo y Julieta , la generación de Sarmiento sólo veía a París a través de los
trio la fuente de su inspiración : Sarmiento , por ímpetu interno y porque viví
elace y Clarisse Harlowe . Por eso Sarmiento , frescamente desembarcado en Parí
able ! Siento daros ese mal rato : Sarmiento se quedaba `` con un palmo de boca
, esa reminiscencia ? Para ellos , Sarmiento no figura , acaso , entre esas _co
Podremos variar el tamaño del contexto en el ancho y en la cantidad de ocurrencias.
text.concordance("Sarmiento", width=132, lines=20)
Displaying 20 of 78 matches:
, en vísperas de la organización nacional . Contemporáneo de Sarmiento , Vicente F. López y Alberdi , perteneció a la generación de
eputo el más puro y castizo de nuestros escritores de nota . Sarmiento era demasiado impetuoso para mantener una corrección inalter
e había cesado de figurar en la escena política de su país . Sarmiento en París Salgo del taller de Rodin ; la figura de Sarmiento
Sarmiento en París Salgo del taller de Rodin ; la figura de Sarmiento va tomando vida y forma . El soberbio viejo , que fué uno de
entra a su vida normal , pasado el síncope [ 20 ] y de nuevo Sarmiento surge en mi memoria , como si su personalidad absorbente sal
sin vida , los ocho o diez tomos publicados de las obras de Sarmiento [ 21 ] , haced un esfuerzo sobre vuestro horror de la letra
modelos del género , páginas comparables a algunas de las de Sarmiento en sus _Viajes_ , al retrato de don Domingo de Oro , en sus
) 51 y no contienen una página que no haya sido escrita por Sarmiento ; hay muy poco inédito , porque para Sarmiento , escribir er
o escrita por Sarmiento ; hay muy poco inédito , porque para Sarmiento , escribir era obrar . Así , en esa publicación , en la que
ea que produzca la impresión dolorosa de una profanación . I Sarmiento se embarca , pues , sobre la _Enriqueta_ , uno de esos barco
or si los pescados le miran , a don Bernardino Rivadavia ... Sarmiento descubre , al pasar , la isla de Robinson , que describe en
ca a que ha dedicado sus últimos años de vigor intelectual . Sarmiento pasa rápidamente por Montevideo , pero su sensación es tan f
ni de nuestro nombre el sello de nobleza de ese abolengo ... Sarmiento venía de Chile , a donde los últimos rebotes de la ola de ba
barco que le llevaba a Río de Janeiro , en rumbo a Europa , Sarmiento debió sacudir su poderosa cabeza , como para disipar el mal
que en nuestra tierra leéis , conocéis el estilo general de Sarmiento , ese ímpetu un tanto desordenado , aquel atropellarse de la
corregíamos en el «Nacional» las pruebas de los artículos de Sarmiento . Allí se topa también con el _pardejón_ Rivera , el tenient
hija doña María da Gloria , pero que él se había resistido . Sarmiento le toma el pelo en el acto y deplora que haya desdeñado de e
no de Europa , pequeño , pero confortable ... II Al fin pisa Sarmiento tierra de Europa , remonta el Sena y por Rouen , gana París
ra entre nosotros . Cuando tuve el honor de ser compañero de Sarmiento en el Consejo General de Educación de la provincia de Buenos
del bastón de su vejez ... La primera impresión de París que Sarmiento comunica a Aberastain es característica ; como el joven que
Obtener las colocaciones.
Las colocaciones son una unidades fraseológicas de dos o más palabras que se usan muy habitualmente combinadas, más de lo que probabilísticamente se daría, por ejemplo “alto riesgo”, “renta fija”, “tomar en cuenta”, “sin duda”, etc.
text.collocations()
Project Gutenberg-tm; Buenos Aires; todos los; Project Gutenberg; más
tarde; todas las; Sr. Abeille; Literary Archive; tal vez; Gutenberg-tm
electronic; electronic works; Gutenberg Literary; San Martín; Archive
Foundation; sin duda; United States; los ojos; primera vez; los
hombres; día siguiente
Podemos asimismo variar la cantidad a mostrar text.collocations(num=50)
Similitud distribucional
Es decir hallar palabras que aparecen en los mismos contexto de una palabra específica:
text.similar("estilo")
colegio espíritu libro estudio día gobierno arte punto sueño silencio
ideal cuerpo éxito abeille suelo cansancio cielo alma patio objetivo
Obtener los hapaxes
Que no son más que una palabra que sólo aparece una vez dentro de un contexto, ya sea en el registro escrito de un idioma entero, en las obras de un autor o dentro de un solo texto.
# Obtener 20 hapaxes
from nltk import FreqDist
fdist1 = FreqDist(text)
fdist1.hapaxes()[:20]
Palabras más comunes
Como hemos visto el objeto FreqDist representa la distribución de los tokens en nuestro Corpus, y podemos usarlo para obtener los términos más comunes, que normalmente son los articulos y preposiciones, sin embargo podemos jugar con la longitud de los tokens a listar para obtener el ranking de otros tipos de palabras
from nltk import FreqDist
fdist1 = FreqDist(text)
print([i for i in fdist1.most_common(1000) if len(i[0]) > 5])
** Otras opciones interesantes de FreqDist **
- fdist.samples(): Genera una lista con el vocabulario
- fdist.values(): Devuelve el no de veces que aparece cada palabra
- fdist.N(): No total de palabras en el texto
- fdist.freq(word): Devuelve la frecuencia de aparación de word
- fdist.inc(palabra): Incrementa la cuenta para una palabra
- fdist.max(): Palabra con máxima frecuencia
- fdist.tabulate(): Tabula la distribución de frecuencia
- fdist.plot(): Representación gráfica
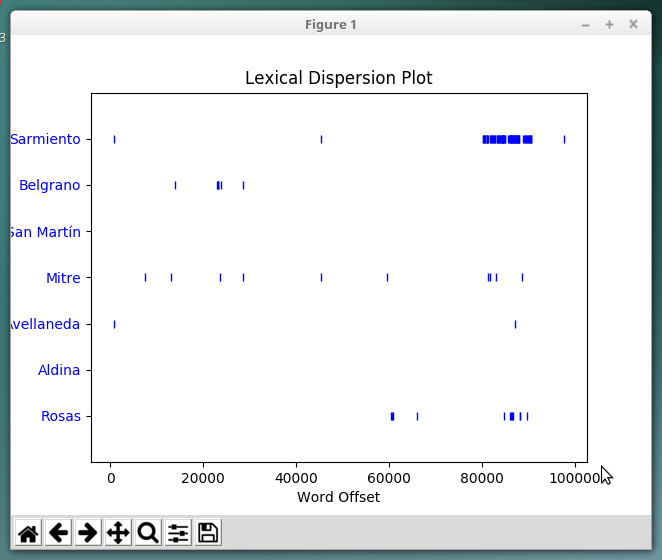
Dispersión lexica
Si además de nltk hemos instalado matplotlib hay un análisis gráfico muy interesante que es la dispersión de determinadas palabras en todo el corpus. Por ejemplo, en la obra de Miguel Cané que estamos usando como ejemplo, podríamos analizar como se organizan los nombres de ciertos próceres en el texto, dónde y cuanto aparecen, por ejemplo:
text.dispersion_plot(["Sarmiento", "Belgrano", "San Martín", "Mitre", "Avellaneda", "Aldina", "Rosas"])
Y esto nos generaráun gráfico como el siguiente:
Riqueza léxica
Este es un dato muy lindo que podemos calcular muy fácilmente sobre cualquier texto. La riqueza léxica representa la variedad de términos usados en un texto con relación a la cantidad total, la fórmula:
def riqueza_lexica(text):
return len(set(text)) / len(text)
Comparemos un poco por ejemplo el texto “Juvenilla” con los “Hermanos Karamazov”
riqueza_lexica(juvenilla)
0.15420297308791675
len(juvenilla)
101107
riqueza_lexica(karamazov)
0.0716456435144911
len(karamazov)
349456
El primer texto tiene una riqueza de 0.15 con algo más de 100.000 palabras, el clasico de Fedor Dostovieski sin embargo tiene un número menor de 0.07 casi la mitad menos pero con el triple de palabras.
Que es el “Stemming” y para que es útil?
El “Stemming” es un algoritmo de reducción de una palabra a su raíz o “stem”. Es muy útil en aplicaciones o funcionalidad de recuperación de información (los buscadores como el de Google usan este mecanismo), pensemos al buscar por el término “familia” usando una búsqueda exacta perderíamos documentos dónde aparecen los términos “familiar”, “familias”, etc. El “Stemming” reduce los términos mencionados a la raíz “famili”, por lo que la búsqueda se hace bastante más precisa.
Datos de interés
Alphabetical list of part-of-speech tags used in the Penn Treebank Project:
| Numero | Etiqueta | Descripción |
| 1. | CC | Coordinating conjunction -> Conjunciones coordinadas |
| 2. | CD | Cardinal number -> Número cardinal |
| 3. | DT | Determiner -> Determinante |
| 4. | EX | Existential there -> Clausula existencial |
| 5. | FW | Foreign word -> Extranjerismo |
| 6. | IN | Preposition or subordinating conjunction -> Preposición o Conjunciones subordinantes |
| 7. | JJ | Adjective -> Adjetivo |
| 8. | JJR | Adjective, comparative -> Adjetivo Comparativo |
| 9. | JJS | Adjective, superlative -> Superlativo |
| 10. | LS | List item marker -> Enumeración |
| 11. | MD | Modal -> Verbos modales |
| 12. | NN | Noun, singular or mass -> Sustantivo, singular o incontable |
| 13. | NNS | Noun, plural -> Sustantivo, plural |
| 14. | NNP | Proper noun, singular -> Nombre propio, singular |
| 15. | NNPS | Proper noun, plural -> Nombre propio, plural |
| 16. | PDT | Predeterminer -> Predeterminante |
| 17. | POS | Possessive ending -> No hay similar en español, es el ´s de this is Peter´s car
|
| 18. | PRP | Personal pronoun -> Pronombre personal |
| 19. | PR$ | Possessive pronoun -> Pronombre posesivo |
| 20. | RB | Adverb -> Adverbio |
| 21. | RBR | Adverb, comparative Adverbio comparativo |
| 22. | RBS | Adverb, superlative Adverbio superlativo |
| 23. | RP | Particle |
| 24. | SYM | Symbol |
| 25. | TO | to |
| 26. | UH | Interjection ->Interjección |
| 27. | VB | Verb, base form |
| 28. | VBD | Verb, past tense |
| 29. | VBG | Verb, gerund or present participle |
| 30. | VBN | Verb, past participle |
| 31. | VBP | Verb, non-3rd person singular present |
| 32. | VBZ | Verb, 3rd person singular present |
| 33. | WDT | Wh-determiner |
| 34. | WP | Wh-pronoun |
| 35. | W$ | Possessive wh-pronoun |
| 36. | WRB | Wh-adverb |