
Gráficos en mapas con R
11 May 2017 16 minsA raíz de esta pregunta en StackOverflow se me dió por investigar las posibilidades que brinda Leaflet en R. La idea es jugar con alguna estadística y hacer un “mapa de calor” sobre un mapa geográfico. Decidí arrancar con una muy triste y lamentablemente instalada que es, la estadística de los femicidios.
Los datos a graficar
En datos.jus.gob.ar publican una muy completa lista de casos de femicidios en la República Argentina, con hechos desde el año 2008 y con una actualización mensual. Lo que lo primero que vamos a ser es buscar el enlace en la página al último archivo e importarlo a nuestro entorno R.
library(rgdal)
library(leaflet)
library(dplyr)
library(magrittr)
# Descarga del registro de femicidio
url <- "http://datos.jus.gob.ar/dataset/27bb9b2c-521b-406c-bdf9-98110ef73f34/resource/583cec9a-3022-4234-8b32-17692a267aac/download/registro-de-femicidios-20200109.csv"
file <- file.path(".", "data",basename(url))
download.file(url, file)
# Carga el Csv a un data.frame
femicidios <- read.table(file = file, header = TRUE, sep = ',', stringsAsFactors = FALSE)
glimpse(femicidios)
Observations: 1,325
Variables: 10
$ caso_numero <int> 310, 402, 237, 565, 594, 703, 38, 31, 44, 14, 18, 8, 35, 36, 13, 20, 22, …
$ victima_edad <int> 47, 7, 18, 46, 27, 42, 22, 41, NA, NA, 44, 45, 32, 10, 18, 34, 33, 33, 40…
$ victima_identidad_genero <chr> "MUJER", "HOMBRE", "MUJER", "MUJER", "MUJER", "MUJER", "MUJER", "MUJER", …
$ victima_tipo <chr> "PRINCIPAL", "VINCULADO", "PRINCIPAL", "PRINCIPAL", "PRINCIPAL", "PRINCIP…
$ hecho_provincia <chr> "Río Negro", "Córdoba", "Santa Fe", "", "Neuquén", "Buenos Aires", "Entre…
$ hecho_modalidad_comisiva <chr> "GOLPES", "ACUCHILLAMIENTO", "DISPARO DE BALA", "QUEMADURAS", "DISPARO DE…
$ hecho_fecha <chr> "2014-11-20", "2015-08-04", "2014-11-02", "2016-01-22", "2016-01-24", "20…
$ fuente_tipo <chr> "MEDIO COMUNICACIÓN", "MEDIO COMUNICACIÓN", "MEDIO COMUNICACIÓN", "MEDIO …
$ fuente_link <chr> "http://www.diariouno.com.ar/policiales/una-mendocina-fue-asesinada-su-pa…
$ hecho_provincia_id <int> 62, 14, 82, NA, 58, 6, 30, 14, 66, 6, 2, 50, 18, 30, 6, NA, 14, 22, 14, 1…
Lo que me interesa hacer, es “mapear” estos datos con la provincia/estado en dónde ocurrió el crimen, para esto lo primer que hay que hacer es normalizar los nombres de las provincias ya que pareciera ser que no son muy rigurosos con estos datos, a veces cargan como Santa Fé y otras como Santa Fe, asimismo hay que unificar los nombres con el del archivo de polígonos geograficos que vamos a usar para que cada provincia tenga el mismo nombre. Bueno esta “normalización” la haremos así:
# Estandarización de los nombres de provincias
femicidios$hecho_provincia <- gsub('Ciudad Autónoma de Bs.As.', 'Ciudad de Buenos Aires', femicidios$hecho_provincia)
femicidios$hecho_provincia <- gsub('Entre Rios', 'Entre Ríos', femicidios$hecho_provincia)
femicidios$hecho_provincia <- gsub('Santa Fé', 'Santa Fe', femicidios$hecho_provincia)
femicidios$hecho_provincia <- gsub('Tucuman', 'Tucumán', femicidios$hecho_provincia)
femicidios$hecho_provincia <- gsub('Neuquen', 'Neuquén', femicidios$hecho_provincia)
femicidios_x_provincia <- as.data.frame(table(femicidios$hecho_provincia), stringsAsFactors = FALSE)
El mapa geográfico
Como ya comenté vamos a usar Leaflet para armar el mapa y colorearlo luego. Para poder usar esta librería, si no la tenemos instalada, simplemente con un install.packages("leaflet") alcanza. Además necesitaremos algún que otro paquete, detallando:
-
leaflet: Es la librería que generara el mapa para incorporar en una vista HTM.
install.packages("leaflet") -
rgdal: Unos “bindings” a la librería de abstracción de datos geográficos de Frank Warmerdam.
install.packages("rgdal")
Bien, para empezar necesitamos obtener un shapefile esto es básicamente (entre otras cosas) una definición de polígonos que nos va permitir establecer las áreas de un mapa que corresponden a cada estado/provincia. Esta información la podemos obtener por ejemplo de biogeo, vamos a usar los “Global Administrative Boundaries (GADM)”, que justamente definen los contornos de los estados en cada país. Vamos a buscar puntualmente el de Argentina.
# Descarga del Shapefile de Argentina
tmp <- tempdir()
url <- "http://biogeo.ucdavis.edu/data/diva/adm/ARG_adm.zip"
file <- file.path(".", "data",basename(url))
download.file(url, file)
unzip(file, exdir = tmp)
argentina <- readOGR(dsn = tmp, layer = "ARG_adm1", use_iconv=TRUE, encoding='UTF-8', stringsAsFactors=FALSE)
Básicamente descargamos el archivo a una carpeta temporal y lo descomprimimos. Hay que analizar el contenido para ubicar el “layer”, que no es más que un clásico archivo DBF, analizándolo pude detectar que se trataba de “ARG_adm1” el que contenía las definiciones de los 24 estados del país. Lo siguiente es usar readOGR una función del paquete rgdal que simplemente transforma el archivo DBF en un vector de datos geo-espaciales.
Combinando datos y geografía
En esta instancia tenemos datos estadísticos en nuestro data.farme femicidios_x_provincia y tenemos la información geográfica en un vector del tipo SpatialPolygonsDataFrame llamado argentina. Ambos vectores comparten una dato común que es el nombre de la provincia, que aprovecharemos entonces para combinar los mismos.
Para combinar las dos fuentes de información primero debemos normalizar el nombre del campo de provincia, para que luego un “merge” nos funcione fácilmente, para esto simplemente a femcidios modificamos la columna “lugar_hecho” por “NAME_1”, con este simple cambio ya podemos combinar la información. Importante: el merge común de R no me funciono del todo bien ya que el resultado final modificaba el orden de los datos, lo que producía que al graficar las provincias salieran mal identificadas. Por lo que optamos por la función join de plyr que es bastante más poderosa.
# Renombrar las columnas para hacer merge
colnames(femicidios_x_provincia) <- c("NAME_1", "Femicidios")
# Merge de los datos
argentina@data <- left_join(argentina@data,femicidios_x_provincia, by = c("NAME_1"))
head(argentina@data[c(1,2,3,4,5,11)])
ID_0 ISO NAME_0 ID_1 NAME_1 femPob
1 12 ARG Argentina 1 Buenos Aires 22223
2 12 ARG Argentina 2 Córdoba 14442
3 12 ARG Argentina 3 Catamarca 12969
4 12 ARG Argentina 4 Chaco 11964
5 12 ARG Argentina 5 Chubut 12867
6 12 ARG Argentina 6 Ciudad de Buenos Aires 36247
Por último, la parte linda y divertida de todo esto:
pal <- colorQuantile("YlGn", NULL, n = 5)
state_popup <- paste0("<strong>Estado: </strong>",
argentina$NAME_1,
"<br><strong>Femicidios: </strong>",
argentina$Femicidios)
leaflet(data = argentina) %>%
addProviderTiles("CartoDB.Positron") %>%
addPolygons(fillColor = ~pal(femicidios_x_provincia$Femicidios),
fillOpacity = 0.8,
color = "#BDBDC3",
weight = 1,
popup = state_popup)
Y obtenemos algo como esto:
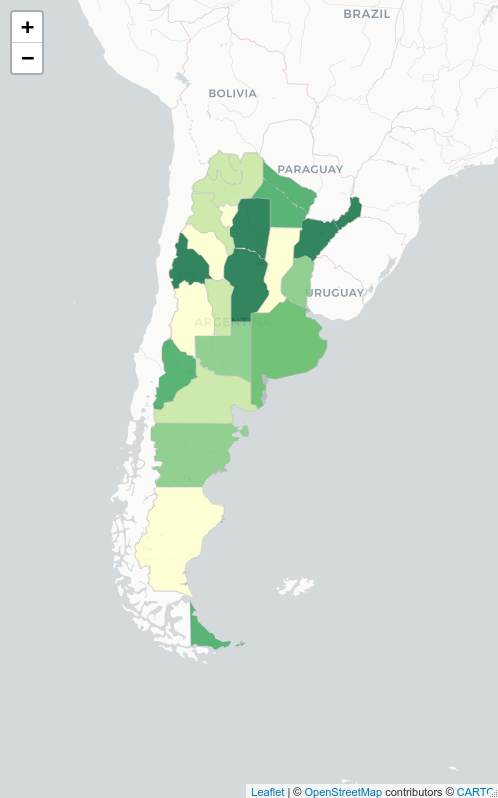
Este gráfico tiene un problema, hay una variable “oculta” que puede inducir al error, lo que ocurre que nos puede hacer suponer, que iertas provincias están más complicadas en cuanto al nivel de femicidios (son las del tono verde más oscuro), pero lo cierto es que tambien los niveles de población son distintos en cada una. Por lejos Buenos Aires es la de mayor población, por lo que el número de femicidios sería bueno ponderarlo en función a esto. La idea ahora sería simplemente tomar el número duro de femicidios y dividirlo por algún indicador con respecto al nivel de población femenina.
Vamos a ir a buscar los datos del último censo de población del año 2010, el Indec maneja unas proyecciones de población por género y provincia que nos van a ser muy útiles, las vamos a descargar de este, los datos son básicamente una planilla Excel nada amigable para hacer trabajarla, por lo que ya la procesé para que sea más cómoda, se puede descargar desde aquí enlace.
url <- "https://raw.githubusercontent.com/pmoracho/R/master/femicidios.ar/data/poblacion.csv"
file <- file.path(".", "data", basename(url))
download.file(url, file)
poblacion <- read.csv(file, stringsAsFactors = FALSE)
Con esto, tenemos un data.frame como el siguiente:
> glimpse(poblacion)
Observations: 744
Variables: 5
$ year <dbl> 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024, …
$ total <chr> "3028481", "3033639", "3038860", "3044076", "3049229", "3054267", "3059122", "3063728", "3…
$ varones <chr> "1405566", "1409835", "1414105", "1418339", "1422507", "1426582", "1430531", "1434323", "1…
$ mujeres <chr> "1622915", "1623804", "1624755", "1625737", "1626722", "1627685", "1628591", "1629405", "1…
$ cod_prv <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
Ahora, teniendo la proyección de mujeres del año 2017, lo que hacemos es agregar todos los datos al shapefile original
# Merge de los datos
nyear = 2020
argentina@data %>%
left_join(poblacion %>%
filter(year == nyear) %>%
select(provincia, mujeres), by= c("NAME_1" = "provincia")) %>%
mutate(femPob = round(mujeres/Femicidios)) %>%
select(-mujeres) -> argentina@data
Cambiamos un poco el estilo de gráfico y gráficamos en función de: argentina$femPob, es decir los femicidios en función de la cantidad de mujeres
pal <- colorQuantile(palette = "Blues", domain = NULL, n = 5, reverse = TRUE)
state_popup <- paste0("<strong>Provincia: </strong>",
argentina$NAME_1,
"<br><strong>1 femicidio cada </strong>",
argentina$femPob,
" <strong>mujeres</strong>")
leaflet(data = argentina) %>%
addProviderTiles("CartoDB.Positron") %>%
addPolygons(fillColor = ~pal(femPob),
fillOpacity = 0.8,
color = "#BDBDC3",
weight = 1,
popup = state_popup)
Y aquí el resultado final:
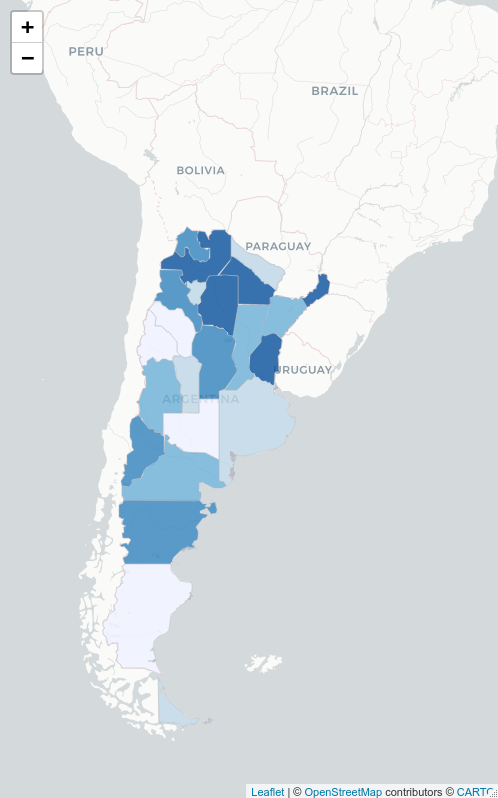
Ahora si podemos ver realmente en que provincias los femicidios son más significativos..
La descarga final de los scripts puede hacerse desde aquí