
Evaluación No Estándar en R
4 Feb 2019 23 minsHacía rato que no publicaba ni escribía nada y me dieron ganas. Nada mejor que hacerlo sobre un tema que me sorprendió mucho al terminar de entenderlo (algo al menos), como es la evaluación de expresiones en R. Digo que me sorprendió, por que entender como R evalúa las expresiones y la forma en que podemos, como programadores, “intervenir” en este proceso, es darse cuenta que es posible (en R) modificar directamente la forma “estándar” y “natural” de evaluación. Esto es algo único, al menos para mí y mi limitado conocimiento en lenguajes. Como programador, darse cuenta de esto, es como un “cross a la mandíbula” ([Arlt] dixit), un golpe inmediato al sentido común, formado por años de trabajo en tantos otros lenguajes: C, C++, Java, Basic, Python, SQL, etc.
En la mayoría de los lenguajes de programación, sólo se puede acceder a los valores de los parámetros de una función. En R, también se puede acceder al código utilizado para calcularlos. Esto hace posible evaluar el código en formas no estándar: usar lo que se conoce como evaluación no estándar, o ENE para abreviar. ENE es particularmente útil para las funciones de análisis interactivo de datos porque puede reducir drásticamente la cantidad de escritura.
Hadley Wickham - Advance R
Para empezar, digamos que todos estos lenguajes (también R) evalúan lo que ingresamos por teclado de una forma prácticamente idéntica, la llamaremos evaluación estándar, pero en R en particular se puede llegar a modificar esto, de una forma muy útil a la que llamaremos evaluación No estándar.
Es sin duda un tópico avanzado, posiblemente nunca te encuentres con necesidad de aplicarlo, pero estoy seguro, que si has escrito algo de código en R, ya lo has usado. Tal vez no te haya llamado la atención cosas como estas:
library(tidyverse)
mtcars %>% group_by(cyl)
subset(ToothGrowth, supp == "VC")
ggplot(df, aes(x=Y2003, y=Y2016)) + geom_point()
Son cuatro expresiones bastante ordinarias, sin embargo todas tiene la particularidad que están haciendo uso de la evaluación No estándar, a partir de ahora la llamaremos ENE en contraste con la estándar que llamaremos ES.
¿Qué es una evaluación?
Si nos guiamos por lo que dice la RAE, sería “Acción de estimar, apreciar o calcular el valor de algo”, nada mal como definición, pero para ser más justos, en el caso de cualquier lenguaje de programación, podríamos decir que la evaluación es el proceso de interpretación de una o mas sentencias ingresadas por el usuario. No importa si el lenguaje es “interpretado” como R o “compilado” como C, existe en cada caso un proceso que interpreta el código escrito en dicho lenguaje. Este proceso de evaluación se compone de múltiples subprocesos, cada compilador o interprete se encargará a su manera de hacerlo, pero a los efectos de este artículo, nos basta con tener claro que la evaluación es la interpretación de un código ingresado y escrito en un lenguaje en particular.
¿Y la evaluación estándar?
Hay algunos rasgos en la forma de evaluar las sentencias que son comunes en casi todos los lenguajes, tan comunes que podríamos considerarlos tan universales como la fuerza de gravedad. Veamos:
> print("mi_variable")
[1] "mi_variable"
> print(mi_variable)
Error in print(mi_variable) : object 'mi_variable' not found
Ningún programador, ni los menos avispados, debería tener dificultad en explicar lo que está ocurriendo, no importa de que lenguaje venga, es absolutamente claro. En la primer expresión, lo que se intenta es mostrar por consola o pantalla, una cadena fija (“hardcoded” le diríamos). R (y cualquier otro lenguaje) “ve” las comillas dobles y evalúa que lo que sigue es una cadena literal.
El segundo caso, vemos que mi_variable no tiene comillas, ¿que hace el interprete de R (y nuevamente el de cualquier otro lenguaje”)? Evalúa que lo que se estaría indicando es un identificador, un nombre, o más precisamente el nombre de un objeto. En este caso mi_variable sin las comillas, es una referencia y no una cadena literal. El mensaje de error luego de print(mi_variable) nos está claramente confirmando esto, no está diciendo que el objeto mi_variable no existe. Claro, si hasta ahora no lo hemos definido. Lo podemos hacer:
> mi_variable <- "Este es el valor al que apunta el objeto llamado mi_variable"
> print(mi_variable)
[1] "Este es el valor al que apunta el objeto llamado mi_variable"
Y ahora sí, tenemos una sentencia que el interprete puede evaluar sin ningún error aparente. Estos son rasgos del lo que llamaríamos Evaluación estándar (ES).
Un pequeño adelanto de lo que se trata todo esto:
> library(tidyverse)
> any(ls() == "tidyverse")
[1] FALSE
Notesé que la cadena tidyverse lo hemos indicado sin comillas como parámetro de entrada de la función library(), la cual realiza la carga de un determinado paquete o librería. Con la siguiente sentencia any(ls() == "tidyverse"), verificamos que no existe ningún objeto llamado tidyverse y a pesar de esto, la función library(), de foma “mágica”, logró entender que lo que queríamos era cargar el paquete tidyverse. Está “magia” se llama Evaluación No estándar (ENE), library() la implementa para evaluar los parámetros de entrada, pero también es capaz de evaluar de la forma estándar, es decir: library("tidyverse") es totalmente válido.
Así como lo cuento, parece un tema casi trivial y no demasiado útil, limitado a la utilidad de usar o no comillas, pero es mucho más que esto y lo iremos viendo paso a paso. A modo de adelanto, comparemos dos formas de hacer exactamente lo mismo:
mtcars[mtcars$cyl>=6 & mtcars$disp > 160 & mtcars$mpg > 15 &
mtcars$hp > 120 & mtcars$gear == 3, ]
subset(mtcars, cyl >=6 & disp > 160 & mpg > 15 & hp > 120 & gear == 3)
Un simple filtro complejo de datos, si usamos la función [ debemos ser muy específicos a la hora de escribir las condiciones, podemos ver que escribimos en todos los casos el nombre del data.frame más $ y el nombre de la columna. Usando subset() que implementa ENE, la escritura es algo más compacta, solo debemos especificar los nombres de columna. Menos caracteres, mejor performance de escritura, y sobre todo menores posibilidades de error.
Lo que termina ocurriendo con subset() y que veremos más adelante es que:
Las condiciones especificadas, se evalúan en el entorno del
data.frameindicado como primer parámetro.
Para llegar a entender esta idea completamente, es necesario entender otros conceptos dónde se apoya toda la teoría de la ENE y que sin duda pueden resultar muy originales para el que venga de otros lenguajes.
Evaluación perezosa de los parámetros de una función
Seguramente has escuchado el término “lazy evaluation”, que hace referencia a una evaluación diferida, una estrategia que se usa en varios lenguajes de programación para retrasar el calculo o ejecución de una expresión hasta el momento en que sea realmente necesario. Digamos, sin profundizar demasiado, que este tipo de estrategia tiene múltiples beneficios. En la gran mayoría de estos lenguajes, este tipo de evaluación debe codificarse especialmente, normalmente, creando objetos que implementan este tipo de evaluación, es decir este tipo de evaluación es un excepción.
Sin embargo, en R la evaluación perezosa es la norma, todo es evaluado de manera “lazy”, y particularmente en esta sección, hablaremos en realidad de la evaluación perezosa de los parámetros de cualquier función, algo que ninguno de los lenguajes mencionados anteriormente lo permite.
En Python por ejemplo, algo como esto, es normalmente aceptado y lo entendemos naturalmente como un error de nuestra parte:
def mi_funcion(a, b):
print("hola")
mi_funcion()
> Traceback (most recent call last):
> File "main.py", line 4, in <module>
> mi_funcion()
> TypeError: mi_funcion() takes exactly 2 arguments (0 given)
Al intentar ejecutar mi_funcion() el interprete evalúa esta, y los parámetros definidos en su firma, como en la llamada no los hemos definido, se nos entrega un mensaje de error muy claro mi_funcion() espera 2 parámetros y no le estamos indicando ninguno.
En R las cosas son un poco distintas (hay que ir acostumbrándose)
mi_funcion <- function(a, b) {
print("hola")
}
mi_funcion()
[1] "hola"
¿Qué absurda magia esta ocurriendo aquí? Tenemos una función que espera dos parámetros, la llamamos sin pasarle ninguno, lo parámetros ni siquiera tienen valores por defecto y no tenemos ningún error y encima la función hace lo que esperaríamos. Aquí es donde vemos la evaluación perezosa de los parámetros de una función. En R, no sé si no lo dijimos ya, todo se evalúa recién cuando realmente lo necesitamos, en este caso, los parámetros no se usan para nada, entonces no se evalúan. Veamos el siguiente caso:
mi_funcion <- function(a, b) {
print(paste("hola", a))
}
mi_funcion()
> Error in paste("hola", a) : argument "a" is missing, with no default
mi_funcion("amigo")
[1] "hola amigo"
mi_funcion("amigo", "del alma")
[1] "hola amigo"
Ahora hemos modificado la función para que use el parámetro a, se usa al llegar a este código print(paste("hola", a)), si invocamos sin pasar este parámetro, obtendremos un error, muy claro también: falta el parámetro a o el mismo no tiene un valor por defecto. También podemos constatar, que si llamamos con este parámetro como lo espera la función, no tendremos ningún error, incluso indicando o no el parámetro b, que vale decir, no se usa en ningún momento.
¿Esto quiere decir que nada de la firma de la función es evaluado previamente? No, algunas cosas si se evalúan, por ejemplo, si indicamos más parámetros de los esperados:
mi_funcion("amigo", "del alma", "como te quiero")
> Error in mi_funcion("amigo", "del alma", "como te quiero") :
> unused argument ("como te quiero")
Dijimos, que todo se evalúa caundo realmente se lo necesita y ¿Cuándo realmente se necesita algo?, bueno hay varios momentos, veamos:
mi_funcion <- function(a, b) {
x = a + b # lo más común una asignación
print(a + b) # El uso colateral en una función
a + b # El retorno implicito de la función
force(a+b) # Pero también se puede forzar la evaluación
}
Cualquiera de las expresiones anteriores dentro de la función, dipararán la evaluación. Una asignación a otra variable, necesita de un valor para colocar en memoria, la acción colateral de la función print(), necesita del valor para mostrarlo en pantalla, el retorno implícito de la función a + b también evalúa la expresión y por último, la función force() evaluará la expresión a pedido.
Y por último, quiero señalar un concepto fundacional para entender la ENE:
Hay un “gap” o intervalo entre la ejecución de la función y el momento en que cualquiera de sus parámetros es evaluado realmente. En este intervalo, nosotros como programadores, podremos intervenir y trabajar sobre estos aún sin necesidad de evaluarlos efectivamente
Entornos
Ya has escrito algo de código en R, pero, puede que aún no te hayas cruzado con el concepto, de environment, pero aunque no lo sepas, apenas iniciada una sesión de R ya los estas usando.
El entorno es un un objeto (como cualquier otro), una estructura de datos muy particular, muy parecida a una lista, que administra:
- Un conjunto de símbolos o si quieres nombres de variables asociados a un determinado contexto de evaluación
- Los objetos o contenido asociado a dichos símbolos
- Y un puntero a un entorno anterior o padre
Cuando inicias una sesión “limpia”, R ya te ofrece un entorno conocido como el entorno global, es decir .GlobalEnv, pero no es más que un “hijo” de varios entornos anteriores
x <- .GlobalEnv
while (environmentName(x) != environmentName(emptyenv())) {
print(environmentName(parent.env(x)));
x <- parent.env(x)
}
[1] "tools:rstudio"
[1] "package:stats"
[1] "package:graphics"
[1] "package:grDevices"
[1] "package:utils"
[1] "package:datasets"
[1] "package:methods"
[1] "Autoloads"
[1] "base"
[1] "R_EmptyEnv"
Cuando se evalúa cualquier sentencia, siempre se lo hace en relación a un determinado contexto, y ese contexto esta vinculado directamente a un entorno. Imaginemos nuevamente una sesión inicial de R con el siguiente código:
mi_suma <- function(a,b) {a + b}
x <- 3
y <- 5
z <- mi_suma(x, y)
z
Si usas RStudio muy probablemente ya conozcas el explorador de entornos, y ejecutando paso a paso el código anterior, también habrás notado, que por cada asignación a una variable, se agrega la misma a la herramienta mencionada, con una particularidad, que viene bien hacer notar: la función, que es también un símbolo como cualquier otra variable, no se incorpora al explorador de entornos, en la definición, sino recién cuando efectivamente es usada: z <- mi_suma(x, y), es la evaluación diferida en acción.
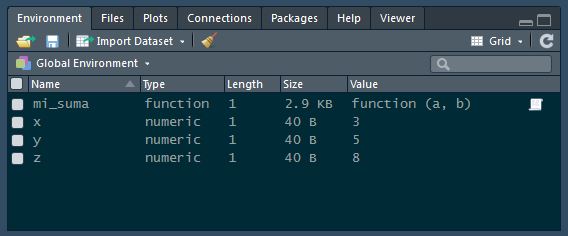
Los entornos tienen una fuerte relación con el scope o contexto. Un patrón común en la mayoría de los lenguajes, es que el código de una función se ejecuta en un contexto distinto al del código desde dónde se la invoca. De ahí que se hable de variables locales, por aquellas que se definen dentro de una función y globales a las que se encuentra definidas fuera de la función. Las variables locales solo son “visibles” dentro de la función y a menos que las retornemos, no pueden accederse fuera de la misma, por otro lado, en muchos lenguajes, que una función acceda a una variable global requiere algún tipo de indicación especial.
En R, ocurre lo mismo, pero con la particularidad, que al ejecutarse una función, de forma transparente para el usuario, se crea automáticamente un entorno, en principio, digamos que vacío de contenido y efímero, durará lo que duré la ejecución de la función.
Ya comentamos que el entorno es un objeto más, por lo que podremos acceder en todo momento a ellos, es decir podemos ver y modificar el contexto de evaluación de cualquier código, y muy importante, podremos hacerlo antes de la evaluación en sí.
En R, el contexto de evaluación de cualquier código es totalmente configurable a través de la manipulación del entorno actual de evaluación, o mediante la creación y configuración de un entorno totalmente nuevo.
Quotation (y Quasi-quotation)
Todavía no encontré una traducción agradable a estos términos. Hablar de “citación” y “quasi-citación”, tal vez es lo más cercano, pero no suena bien. Quotation en R es un mecanismo por el cual podemos “capturar” una expresión sin evaluarla. La forma más básica de hacerlo es mediante la función quote():
x + y
Error: objeto 'x' no encontrado
quote(x + y)
x + y
¿Qué podemos deducir de esto? Hay una expresión x + y, en la primer sentencia, el error claramente nos confirma que estamos evaluando la expresión y que aún no hemos definidas las variables x e y. La segunda expresión quote(x + y) funciona correctamente, aún siendo que las variables siguen sin existir, por que en realidad quote() es capaz de capturar la expresión x + y sin evaluarla, producto de la ENE, ni más ni menos. Capturar una expresión, nos permite manejar la evaluación , pero fundamentalmente dos cosas importantes: el Cuando y el Como.
El Cuando nos permite salvar la expresión sin evaluar, en una variable, en un archivo, en una base de datos (¿por que no?), y usarla luego cuando realmente la necesitemos. El Como nos permite manejar el contexto en que se evaluará la expresión pudiendo manipular completamente las variables y el entorno de la propia expresión.
Un ejemplo práctico:
exp <- quote(x + y)
x <- 1
y <- 2
eval(exp)
[1] 3
x <- 5
y <- 2
eval(exp)
[1] 7
exp <- quote(x + y) crea una expresión (no confundir con el objeto del mismo nombre), está expresión o estrictamente hablando, está quotation, se construye pero no se evalúa. La expresión representa la suma de dos variables, las cuales no existen hasta ahora, cuando luego, realmente la evaluamos, el cuando, definimos el contexto de evaluación asignando valores a estas variables, el como, de esta forma en cada evaluación, usando eval(exp), el resultado será consistente con los valores de las variables en dicho momento. En este ejemplo, estamos usando el mismo environment, solo que lo hemos ido modificado (al modificar las variables) previo a cada evaluación.
Ya tenemos una idea, aunque sea muy elemental, de lo que es una quotation: código pendiente de evaluación. ¿Y que es entonces una quasicuotation? Este concepto proviene de las disciplinas lingüísticas, se conoce también como Quine quotation, en honor al filosofo y lógico Willard van Orman Quine. La idea es muy simple, (por favor si hay un lingüista en la sala, no me mate) si tenemos una oración que dice “La adicción es aguda”, ¿de que estamos hablando?, ¿acaso es que la adición de alguien no identificado en la frase, es demasiado profunda y difícil de tratar, o simplemente estamos comentando que la palabra adicción es aguda?
La idea de la quaicuotation es la de definir un estándar para poder indicar cuando una palabra no representa su significado real sino que representa la palabra misma, por ejemplo: “La [adicción] es aguda”, si nuestro estándar es usar los símbolos [], podríamos estar seguros en este caso, que adicción hace referencia a la propia palabra y no a la dependencia a ciertas sustancias.
Volvamos al ejemplo anterior:
exp <- quote(x + y)
Ahora supongamos que nuestra idea, es evaluar x de forma diferida, pero y en el momento de quote(), es decir, queremos que y se comporte como una constante en la evaluación diferida. Por supuesto, podríamos indicar el valor literal, supongamos que y queremos que sea 10, entonces podríamos hacer:
exp <- quote(x + 10)
Pero, no, la idea es que en realidad ese valor 10 sea indicado por una variable que resolveremos al principio y no en cada evaluación. Para poder hacer esto es que necesitamos usar “quasicuotation”, veamos como:
y <- 10
exp <- bquote(x + .(y))
x <- 1
paste("El valor de", deparse(exp), "donde x es", x, "es", eval(exp))
[1] "El valor de x + 10 donde x es 1 es 11"
x <- 5
paste("El valor de", deparse(exp), "donde x es", x, "es", eval(exp))
[1] "El valor de x + 10 donde x es 5 es 15"
Algunas cosas que nos dice este código:
- Para poder usar “quasicuotation”, necesitamos:
- Utilizar la función
bquote() - Utilizar la notación
.(y)para indicar que la variableydebe ser evaluada para poder construir la expresión
- Utilizar la función
- Con
deparse(exp)conseguimos una representación visual de la expresión - Y con
eval(exp), obviamente evaluamos la expresión
Importante: Todo lo anterior, es apenas un ejemplo muy primitivo, es decir, usando código R base. Tengan en cuenta, que paquetes con dplyr hacen uso de otras funciones más modernas y desarrolladas para implementar lo que se conoce como tidy_avaluation(), que podríamos decir, es la evolución natural de la evaluación NO estándar.
Conclusiones
- Las expresiones se evalúan cuando efectivamente se las necesita (“lazy evaluation”)
- Las expresiones son evaluadas siempre dentro de un determinado contexto, llamado entorno (espacio de memoria)
- El interprete R permite gracias a la evaluación perezosa, capturar una expresión sin evaluarla
- Una expresión capturada, es un objeto como cualquier otro, referenciado por un nombre o variable
- La evaluación puede ser gobernada por nosotros, en el momento que deseemos
- La forma de evaluar una expresión también, modificar el entorno, modifica la evaluación
- Quotation es la acción de capturar una expresión,
- Quasiquotation nos permite indicar que parte de la expresión se evaluará en el momento inicial de la captura de la expresión