Ejemplos de gráficas Ggplot2 con tema personalizado
10 Mar 2019 57 minsHace un tiempo que estoy robando ideas de todos lados como para armar un tema de ggplot2 que sea elegante, simple y visualmente atractivo. Lo llame theme_elegante(), muy original lo mio. El código es el siguiente:
#######################
# CREATING PLOT THEMES
#######################
library(extrafont)
# Create Base Theme
#------------------
theme_elegante <- function(base_size = 10,
base_family = "Raleway"
)
{
color.background = "#FFFFFF" # Chart Background
color.grid.major = "#D9D9D9" # Chart Gridlines
color.axis.text = "#666666" #
color.axis.title = "#666666" #
color.title = "#666666"
color.subtitle = "#666666"
strip.background.color = '#9999CC'
ret <-
theme_bw(base_size=base_size) +
# Set the entire chart region to a light gray color
theme(panel.background=element_rect(fill=color.background, color=color.background)) +
theme(plot.background=element_rect(fill=color.background, color=color.background)) +
theme(panel.border=element_rect(color=color.background)) +
# Format the grid
theme(panel.grid.major=element_line(color=color.grid.major,size=.55, linetype="dotted")) +
theme(panel.grid.minor=element_line(color=color.grid.major,size=.55, linetype="dotted")) +
theme(axis.ticks=element_blank()) +
# Format the legend, but hide by default
theme(legend.position="none") +
theme(legend.background = element_rect(fill=color.background)) +
theme(legend.text = element_text(size=base_size-3,color=color.axis.title, family = base_family)) +
theme(strip.text.x = element_text(size=base_size,color=color.background, family = base_family)) +
theme(strip.text.y = element_text(size=base_size,color=color.background, family = base_family)) +
#theme(strip.background = element_rect(fill=strip.background.color, linetype="blank")) +
theme(strip.background = element_rect(fill = "grey70", colour = NA)) +
# theme(panel.border= element_rect(fill = NA, colour = "grey70", size = rel(1)))+
# Set title and axis labels, and format these and tick marks
theme(plot.title=element_text(color=color.title,
size=20,
vjust=1.25,
family=base_family,
hjust = 0.5
)) +
theme(plot.subtitle=element_text(color=color.subtitle, size=base_size+2, family = base_family, hjust = 0.5)) +
theme(axis.text.x=element_text(size=base_size,color=color.axis.text, family = base_family)) +
theme(axis.text.y=element_text(size=base_size,color=color.axis.text, family = base_family)) +
theme(text=element_text(size=base_size, color=color.axis.text, family = base_family)) +
theme(axis.title.x=element_text(size=base_size+2,color=color.axis.title, vjust=0, family = base_family)) +
theme(axis.title.y=element_text(size=base_size+2,color=color.axis.title, vjust=1.25, family = base_family)) +
theme(plot.caption=element_text(size=base_size-2,color=color.axis.title, vjust=1.25, family = base_family)) +
# Legend
theme(legend.text=element_text(size=base_size,color=color.axis.text, family = base_family)) +
theme(legend.title=element_text(size=base_size,color=color.axis.text, family = base_family)) +
theme(legend.key=element_rect(colour = color.background, fill = color.background)) +
theme(legend.position="bottom",
legend.box = "horizontal",
legend.title = element_blank(),
legend.key.width = unit(.75, "cm"),
legend.key.height = unit(.75, "cm"),
legend.spacing.x = unit(.25, 'cm'),
legend.spacing.y = unit(.25, 'cm'),
legend.margin = margin(t=0, r=0, b=0, l=0, unit="cm")) +
# Plot margins
theme(plot.margin = unit(c(.5, .5, .5, .5), "cm"))
ret
}
Y a continuación algunos ejemplos de gráficas tradicionales de ggplot2.
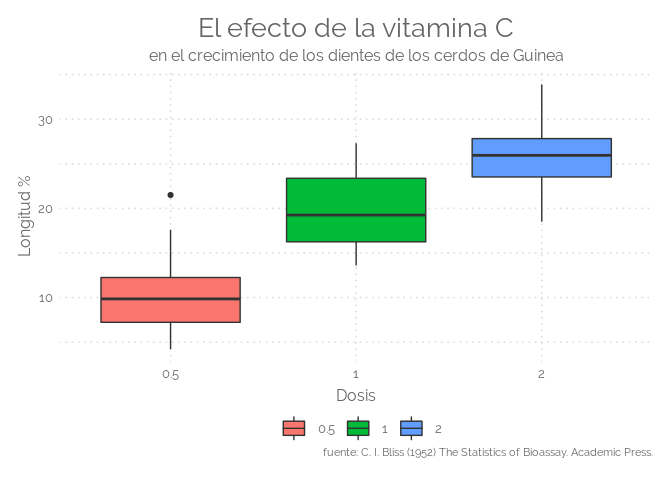
Box plot
El Boxplot es probablemente uno de los tipos de gráficos más comunes. Da un buen resumen de una o varias variables numéricas. La línea que divide la caja en 2 partes representa la mediana de los datos. El final de la caja muestra los cuartiles superior e inferior. Las líneas extremas muestran el valor más alto y el más bajo excluyendo los valores atípicos. Tenga en cuenta que Boxplot oculta el número de valores detrás de la variable. Por lo tanto, es muy recomendable imprimir el número de observaciones, añadir una observación única con fluctuaciones o usar un Violinplot si tiene muchas observaciones.
library(ggplot2)
ggplot(ToothGrowth, aes(x=factor(dose), y=len, fill=factor(dose))) +
geom_boxplot() +
labs(title="El efecto de la vitamina C",
subtitle="en el crecimiento de los dientes de los cerdos de Guinea",
caption="fuente: C. I. Bliss (1952) The Statistics of Bioassay. Academic Press.",
y="Longitud %",
x="Dosis",
color=NULL) + # title and caption
theme_elegante()
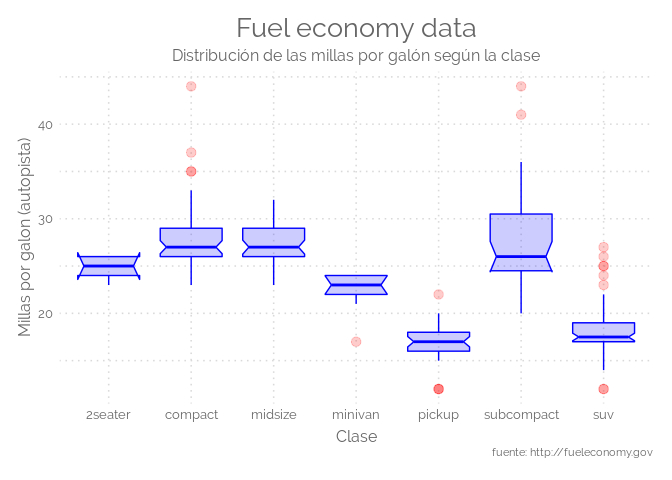
ggplot(mpg, aes(x=class, y=hwy)) +
geom_boxplot(
# custom boxes
color="blue",
fill="blue",
alpha=0.2,
# Notch?
notch=TRUE,
notchwidth = 0.8,
# custom outliers
outlier.colour="red",
outlier.fill="red",
outlier.size=3
) +
labs(title="Fuel economy data",
subtitle="Distribución de las millas por galón según la clase",
caption="fuente: http://fueleconomy.gov",
y="Millas por galon (autopista)",
x="Clase",
color=NULL) + # title and caption
theme_elegante()
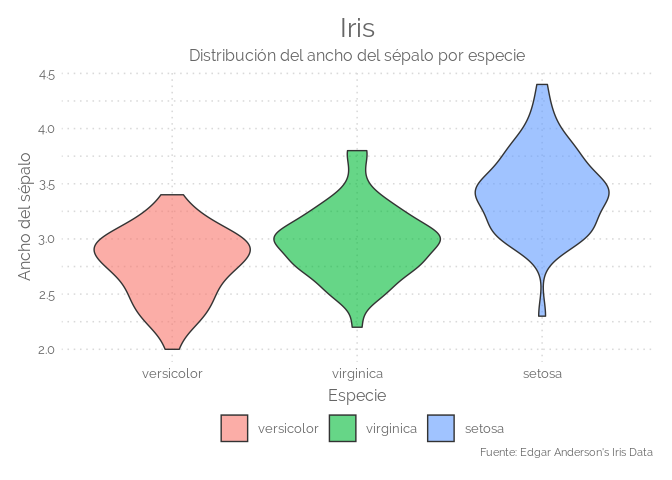
Violin plot
Las gráficas de violín permiten visualizar la distribución de una variable numérica para uno o varios grupos. Está muy cerca de una boxplot, pero permite una comprensión más profunda de la densidad. Los violines se adaptan especialmente cuando la cantidad de datos es enorme y resulta imposible mostrar observaciones individuales. Los gráficos de violín son una forma muy conveniente de mostrar los datos y probablemente merezcan más atención en comparación con los gráficos de caja que a veces pueden ocultar características de los datos.
library(ggplot2)
# reorder is close to order, but is made to change the order of the factor levels.
iris$Species = with(iris, reorder(Species, Sepal.Width, mean))
# Now you can plot
ggplot(iris, aes(x=Species, y=Sepal.Width, fill=Species)) +
geom_violin(alpha=0.6) +
labs(title="Iris",
subtitle="Distribución del ancho del sépalo por especie",
caption="Fuente: Edgar Anderson's Iris Data",
y="Ancho del sépalo",
x="Especie",
color=NULL) +
theme_elegante()
# Second type
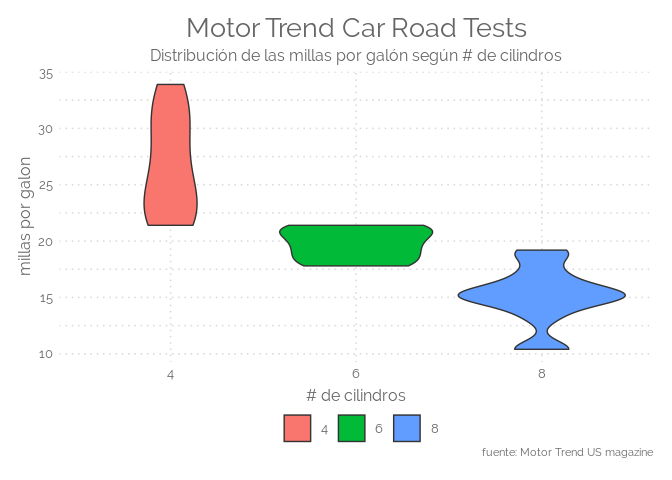
ggplot(mtcars, aes(factor(cyl), mpg)) +
geom_violin(aes(fill = factor(cyl))) +
labs(title="Motor Trend Car Road Tests",
subtitle="Distribución de las millas por galón según # de cilindros",
caption="fuente: Motor Trend US magazine",
y="millas por galon",
x="# de cilindros",
color=NULL) +
theme_elegante()
Scatter plot
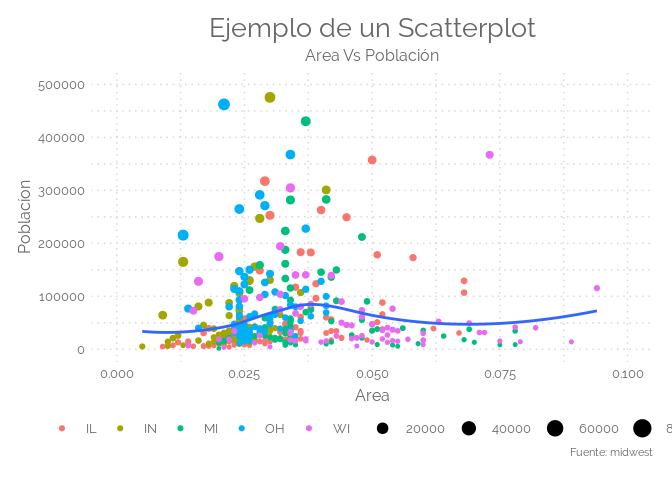
Una gráfica de dispersión (scatterplot) muestra el valor de 2 conjuntos de datos en 2 dimensiones. Cada punto representa una observación. La posición en los ejes X (horizontal) e Y (vertical) representa los valores del valor de 2 variables. Es realmente útil estudiar la relación entre ambas variables. Es común proporcionar aún más información usando colores o formas (para mostrar grupos, o una tercera variable). También es posible mapear otra variable al tamaño de cada punto, lo que hace un gráfico de burbujas. Si tiene muchos puntos y lucha con el sobretrazado, considere la posibilidad de usar un gráfico de densidad en 2D.
library(ggplot2)
options(scipen=999) # turn-off scientific notation like 1e+48
data("midwest", package = "ggplot2")
# Scatterplot
ggplot(midwest, aes(x=area, y=poptotal)) +
geom_point(aes(col=state, size=popdensity)) +
geom_smooth(method="loess", se=F) +
xlim(c(0, 0.1)) +
ylim(c(0, 500000)) +
labs(subtitle="Area Vs Población",
y = "Poblacíon",
x = "Area",
title = "Ejemplo de un Scatterplot",
caption = "Fuente: midwest") +
theme_elegante()
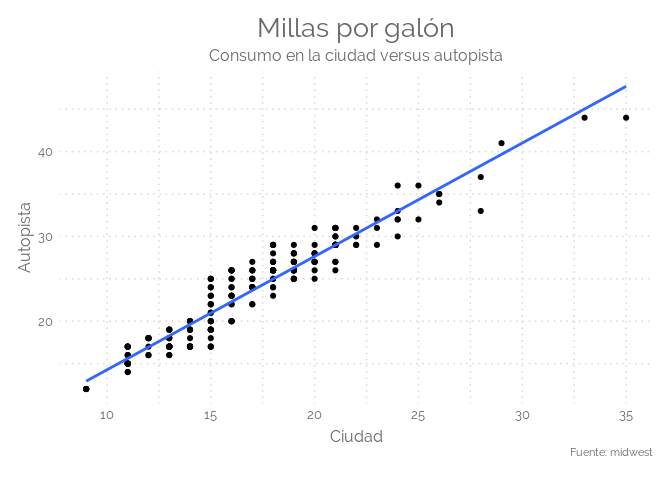
ggplot(mpg, aes(cty, hwy)) +
geom_point() +
geom_smooth(method="lm", se=F) +
labs(subtitle = "Consumo en la ciudad versus autopista",
y = "Autopista",
x = "Ciudad",
title = "Millas por galón",
caption = "Fuente: midwest") +
theme_elegante()
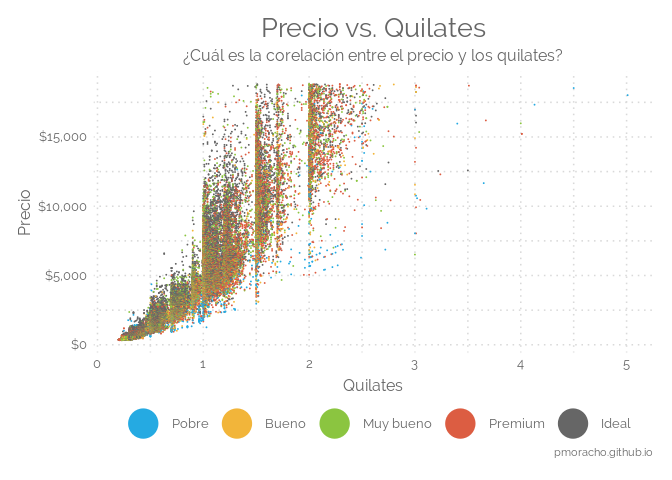
data("diamonds")
levels(diamonds$cut) <- c("Pobre", "Bueno", "Muy bueno", "Premium", "Ideal")
ggplot(data=diamonds, aes(x = carat, y = price, color = cut)) +
geom_point(alpha = 1, size = .01, aes(color = cut)) +
labs(title = "Precio vs. Quilates",
subtitle = "¿Cuál es la corelación entre el precio y los quilates?",
x = "Quilates",
y = "Precio",
caption = "pmoracho.github.io" ) +
scale_color_manual(values=c('#25AAE2','#F2B53A', '#8BC540', '#DC5D42', '#666666', '9FAFBE')) +
guides(colour = guide_legend(override.aes = list(size=10))) +
theme(legend.key = element_rect(colour = "transparent", fill = "white")) +
scale_y_continuous(labels=dollar_format(prefix="$")) +
theme_elegante()
Y también veamos como se ve un “facetado””
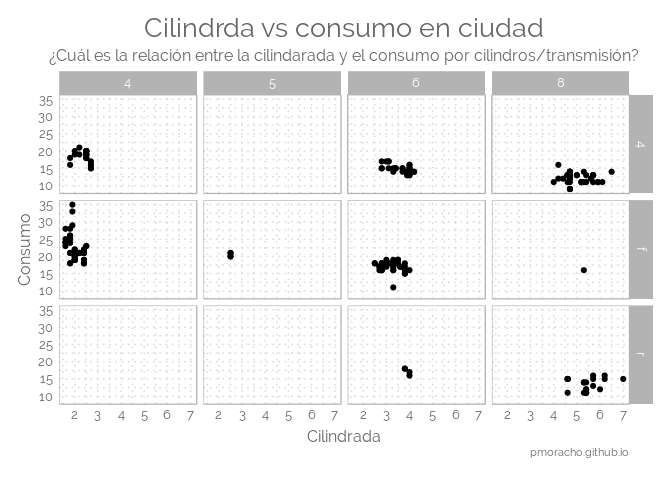
library(ggplot2)
ggplot(mpg, aes(displ, cty)) +
geom_point() +
# Use vars() to supply variables from the dataset:
facet_grid(vars(drv), vars(cyl)) +
theme_elegante() +
theme(panel.border= element_rect(fill = NA, colour = "grey70", size = rel(1))) +
labs(title = "Cilindrda vs consumo en ciudad",
subtitle = "¿Cuál es la relación entre la cilindarada y el consumo por cilindros/transmisión?",
x = "Cilindrada",
y = "Consumo",
caption = "pmoracho.github.io" ) +
scale_color_manual(values=c('#25AAE2','#F2B53A', '#8BC540', '#DC5D42', '#666666', '9FAFBE'))
Connected scatter plot
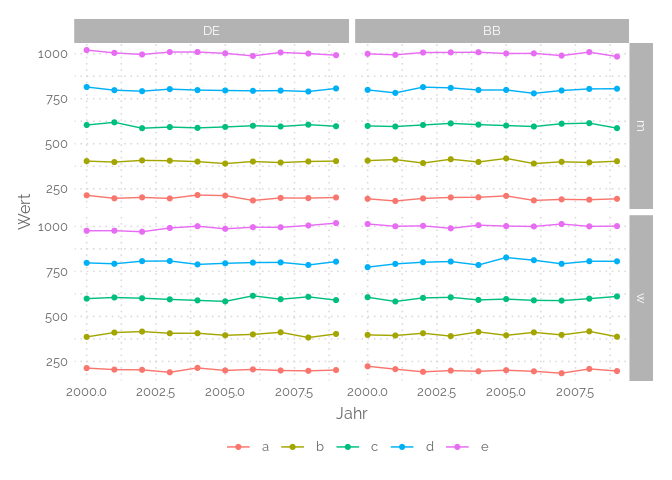
Una gráfica de dispersión conectada está realmente cerca de una gráfica de línea, excepto que cada una de las rupturas en las líneas se muestran usando un punto. También está bastante cerca de la gráfica de dispersión, pero tiene una especificidad: su eje X debe ser ordenado para hacer este tipo de representación. Por lo tanto, las gráficas de dispersión conectadas se utilizan a menudo para series temporales en las que el eje X representa el tiempo. Si desea rellenar el área debajo de la línea, obtendrá un gráfico de área.
tu <- expand.grid(Land = gl(2, 1, labels = c("DE", "BB")),
Altersgr = gl(5, 1, labels = letters[1:5]),
Geschlecht = gl(2, 1, labels = c('m', 'w')),
Jahr = 2000:2009)
set.seed(42)
tu$Wert <- unclass(tu$Altersgr) * 200 + rnorm(200, 0, 10)
ggplot(tu, aes(x = Jahr, y = Wert, color = Altersgr, group = Altersgr)) +
geom_point() +
geom_line() +
facet_grid(Geschlecht ~ Land) +
theme_elegante()
Line graphs / plots
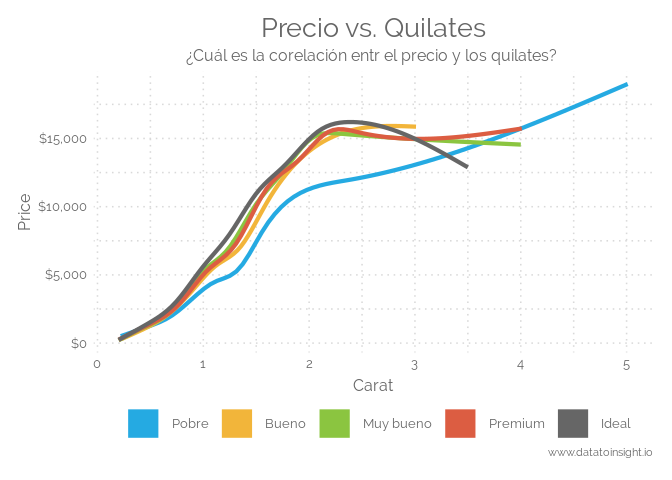
Los gráficos de líneas se utilizan para visualizar valores cuantitativos a lo largo de un intervalo o período de tiempo continuo. Un gráfico de líneas se utiliza con mayor frecuencia para mostrar tendencias y analizar cómo han cambiado los datos con el paso del tiempo. Los gráficos de líneas se dibujan primero trazando puntos de datos en una cuadrícula de coordenadas cartesianas y luego conectando una línea entre todos estos puntos. Típicamente, el eje y tiene un valor cuantitativo, mientras que el eje x es una escala de tiempo o una secuencia de intervalos. Los valores negativos se pueden mostrar debajo del eje x. La dirección de las líneas en el gráfico funciona como una buena metáfora de los datos: una pendiente ascendente indica dónde han aumentado los valores y una pendiente descendente indica dónde han disminuido los valores. El viaje de la línea a través del gráfico puede crear patrones que revelan tendencias en un conjunto de datos. Cuando se agrupan con otras líneas (otras series de datos), las líneas individuales pueden compararse entre sí. Sin embargo, evite usar más de 3-4 líneas por gráfico, ya que esto hace que el gráfico esté más desordenado y sea más difícil de leer. Una solución a esto es dividir el gráfico en múltiplos más pequeños (tener un gráfico de líneas pequeño para cada serie de datos).
fuente: The Data Visualisation Catalogue
library(ggplot2)
library(lubridate)
ggplot(data = diamonds, aes(x = carat, y = price, color = cut)) +
labs(title = "Precio vs. Quilates",
subtitle = "¿Cuál es la corelación entr el precio y los quilates? ",
x = "Carat",
y = "Price",
caption = "www.datatoinsight.io" ) +
scale_color_manual(values=c('#25AAE2','#F2B53A', '#8BC540', '#DC5D42', '#666666', '9FAFBE')) +
guides(colour = guide_legend(override.aes = list(size=10))) +
geom_smooth(alpha = 0.2, size = 1.5, span = 4, se=FALSE) +
theme(legend.key = element_rect(fill = "white")) +
scale_y_continuous(labels=dollar_format(prefix="$")) +
theme_elegante()
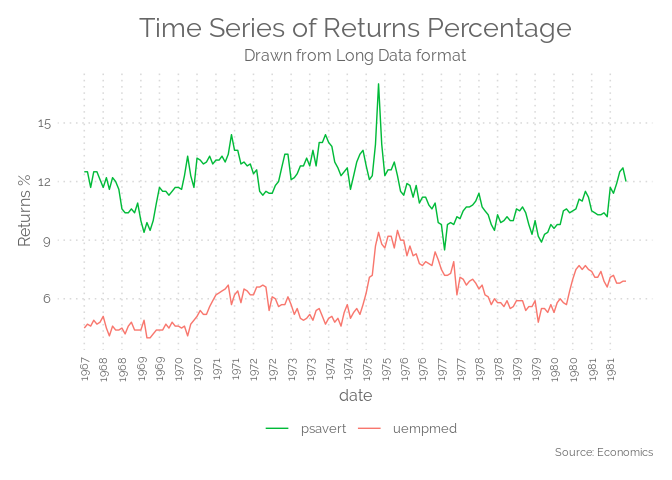
df <- economics_long[economics_long$variable %in% c("psavert", "uempmed"), ]
df <- df[lubridate::year(df$date) %in% c(1967:1981), ]
# labels and breaks for X axis text
brks <- df$date[seq(1, length(df$date), 12)]
lbls <- lubridate::year(brks)
# plot
ggplot(df, aes(x=date)) +
geom_line(aes(y=value, col=variable)) +
theme_elegante() +
labs(title="Time Series of Returns Percentage",
subtitle="Drawn from Long Data format",
caption="Source: Economics",
y="Returns %",
color=NULL) + # title and caption
scale_x_date(labels = lbls, breaks = brks) + # change to monthly ticks and labels
scale_color_manual(labels = c("psavert", "uempmed"),
values = c("psavert"="#00ba38", "uempmed"="#f8766d")) + # line color
theme(axis.text.x = element_text(angle = 90, vjust=0.5, size = 8), # rotate x axis text
panel.grid.minor = element_blank()) # turn off minor grid
Density plot
Un gráfico de densidad muestra la distribución de una variable numérica. Sólo toma como entrada un conjunto de valores numéricos. Está muy cerca de un histograma. Tenga en cuenta que es muy recomendable jugar con el argumento de ancho de banda para no perder un patrón específico en los datos. Tenga en cuenta que puede comparar la distribución de varias variables graficándolas en el mismo eje, usando facetas o a través de un gráfico de gozo.
library(ggplot2)
data("diamonds")
options(scipen=999)
levels(diamonds$cut) <- c("Pobre", "Bueno", "Muy bueno", "Premium", "Ideal")
# plot 1: Density of price for each type of cut of the diamond:
ggplot(data=diamonds,aes(x=price, group=cut, fill=cut)) +
geom_density(adjust=1.5) +
labs(title = "Precio vs. Densidad",
subtitle = "Distribución del precio en relación a la densidad",
x = "Precio",
y = "Densidad",
caption = "Fuente: pmoracho.github.io" ) +
theme_elegante()
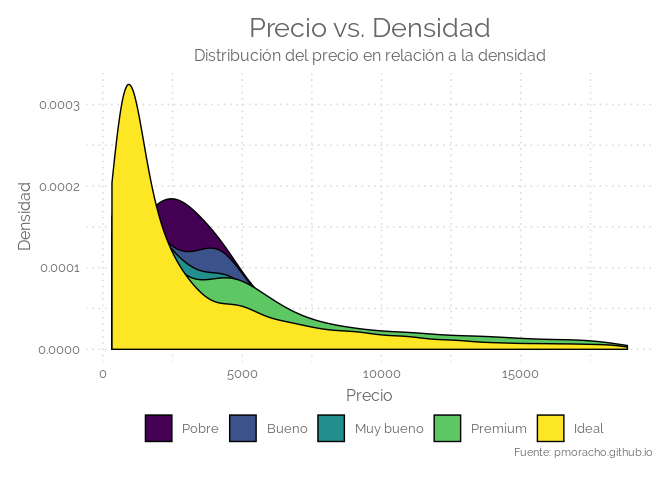
# plot 2: Density plot with transparency (using the alpha argument):
ggplot(data=diamonds,aes(x=price, group=cut, fill=cut)) +
geom_density(adjust=1.5 , alpha=0.2) +
labs(title = "Precio vs. Densidad",
subtitle = "Distribución del precio en relación a la densidad",
x = "Precio",
y = "Densidad",
caption = "Fuente: pmoracho.github.io" ) +
theme_elegante()
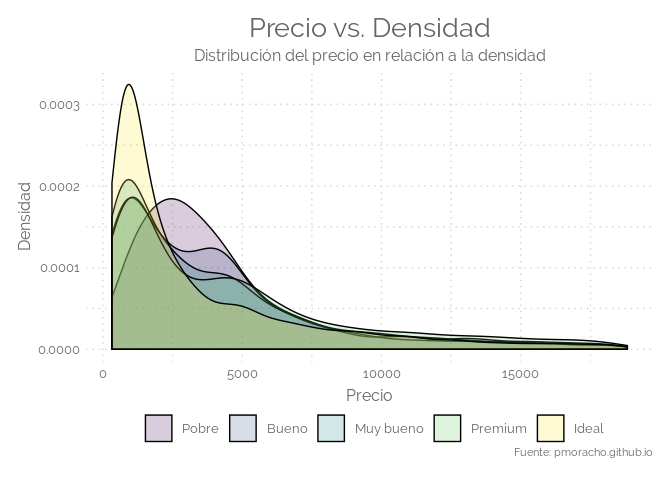
# plot 3: Stacked density plot:
ggplot(data=diamonds,aes(x=price, group=cut, fill=cut)) +
geom_density(adjust=1.5, position="fill") +
labs(title = "Precio vs. Densidad",
subtitle = "Distribución del precio en relación a la densidad",
x = "Precio",
y = "Densidad",
caption = "Fuente: pmoracho.github.io" ) +
theme_elegante()
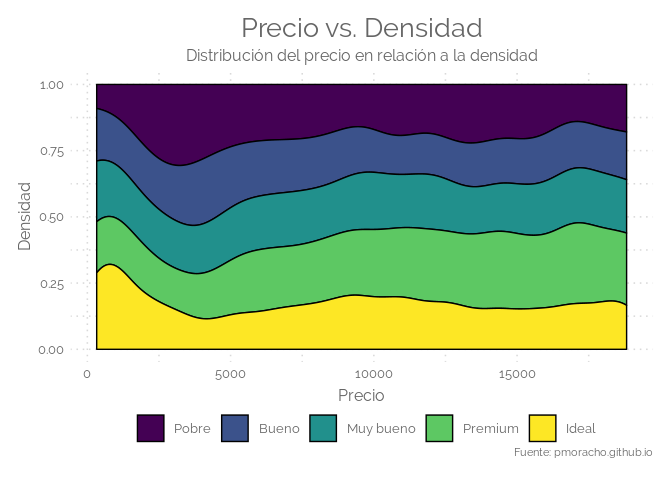
# plot 4
ggplot(diamonds, aes(x=depth, y=..density..)) +
geom_density(aes(fill=cut), position="stack") +
xlim(50,75) +
labs(title = "Precio vs. Densidad",
subtitle = "Distribución del precio en relación a la densidad",
x = "Precio",
y = "Densidad",
caption = "Fuente: pmoracho.github.io" ) +
theme(legend.position="none") +
theme_elegante()
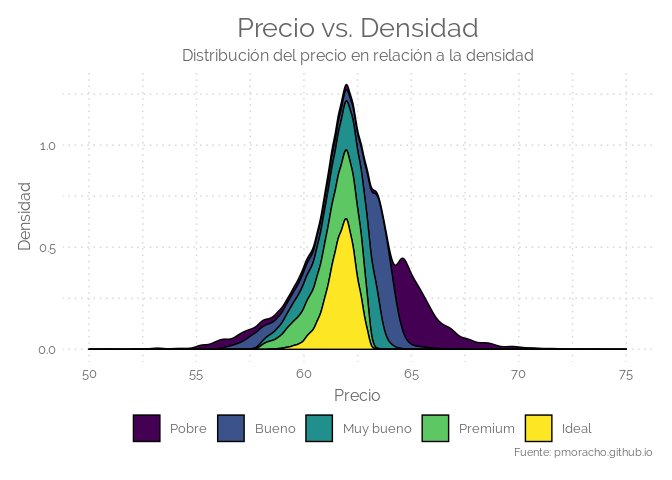
Stacked area chart
Un gráfico de área apilada es la extensión de un gráfico de área básico para mostrar la evolución del valor de varios grupos en el mismo gráfico. Los valores de cada grupo se muestran uno encima del otro. Permite comprobar en una misma figura, la evolución tanto del total de una variable numérica, como de la importancia de cada grupo. Si sólo le interesa la importancia relativa de cada grupo, probablemente debería dibujar un gráfico de área apilada en porcentaje. Tenga en cuenta que esta tabla se vuelve difícil de leer si se muestran demasiados grupos y si los patrones son realmente diferentes entre grupos. En este caso, piense en utilizar facetas en su lugar.
# DATA
library(ggplot2)
set.seed(345)
Sector <- rep(c("S01","S02","S03","S04","S05","S06","S07"),times=7)
Year <- as.numeric(rep(c("1950","1960","1970","1980","1990","2000","2010"),each=7))
Value <- runif(49, 10, 100)
data <- data.frame(Sector,Year,Value)
ggplot(data, aes(x=Year, y=Value, fill=Sector)) +
geom_area() +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="Valor",
x="Año") +
theme_elegante()
ggplot(data, aes(x=Year, y=Value, fill=Sector)) +
geom_area(colour="black", size=.2, alpha=.4) +
scale_fill_brewer(palette="Greens", breaks=rev(levels(data$Sector))) +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="Valor",
x="Año") +
theme_elegante()
my_fun=function(vec){ as.numeric(vec[3]) / sum(data$Value[data$Year==vec[2]]) *100 }
data$prop=apply(data , 1 , my_fun)
ggplot(data, aes(x=Year, y=prop, fill=Sector)) +
geom_area(alpha=0.6 , size=1, colour="black") +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="Valor",
x="Año") +
theme_elegante()
Streamgraphs
Un gráfico Stream está muy cerca de un gráfico de área apilada. Muestra la evolución de un valor numérico (eje Y) en función de otro valor numérico (eje X). Esta evolución está representada por varios grupos, todos con un color distinto. A diferencia de un área apilada, no hay ninguna esquina: los bordes son redondeados, lo que da esta agradable impresión de flujo. Los gráficos de streaming son muy útiles cuando se muestran en modo interactivo: resaltar un grupo le da directamente una idea de su evolución. R permite crear fácilmente gráficos streaming gracias a la biblioteca de gráficos streaming.
library(ggTimeSeries)
library(ggplot2)
set.seed(10)
dfData = data.frame(
Time = 1:1000,
Signal = abs(
c(
cumsum(rnorm(1000, 0, 3)),
cumsum(rnorm(1000, 0, 4)),
cumsum(rnorm(1000, 0, 1)),
cumsum(rnorm(1000, 0, 2))
)
),
VariableLabel = c(rep('Class A', 1000),
rep('Class B', 1000),
rep('Class C', 1000),
rep('Class D', 1000))
)
# base plot
ggplot(dfData,
aes(x = Time,
y = Signal,
group = VariableLabel,
fill = VariableLabel)) +
stat_steamgraph() +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="Señal",
x="Tiempo") +
theme_elegante()
2D density plot
Un gráfico de densidad 2d es útil para estudiar la relación entre dos variables numéricas si tiene un gran número de puntos. Para evitar la superposición (como en la gráfica de dispersión al lado), divide el área de la gráfica en una multitud de pequeños fragmentos y representa el número de puntos en este fragmento.
library(ggplot2)
a <- data.frame( x=rnorm(20000, 10, 1.9), y=rnorm(20000, 10, 1.2) )
b <- data.frame( x=rnorm(20000, 14.5, 1.9), y=rnorm(20000, 14.5, 1.9) )
c <- data.frame( x=rnorm(20000, 9.5, 1.9), y=rnorm(20000, 15.5, 1.9) )
data <- rbind(a,b,c)
# Basic scatterplot
ggplot(data, aes(x=x, y=y) ) +
geom_point() +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="x",
x="y") +
theme_elegante()
ggplot(data, aes(x=x, y=y) ) +
geom_hex() +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="x",
x="y") +
theme_elegante()
# Show the contour only
ggplot(data, aes(x=x, y=y) ) +
geom_density_2d() +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="x",
x="y") +
theme_elegante()
# Show the area only
ggplot(data, aes(x=x, y=y) ) +
stat_density_2d(aes(fill = ..level..), geom = "polygon") +
labs(title="Titulo del gráfico",
subtitle="Subtitulo del gráfico",
caption="Fuente: pmoracho.github.io",
y="x",
x="y") +
theme_elegante()
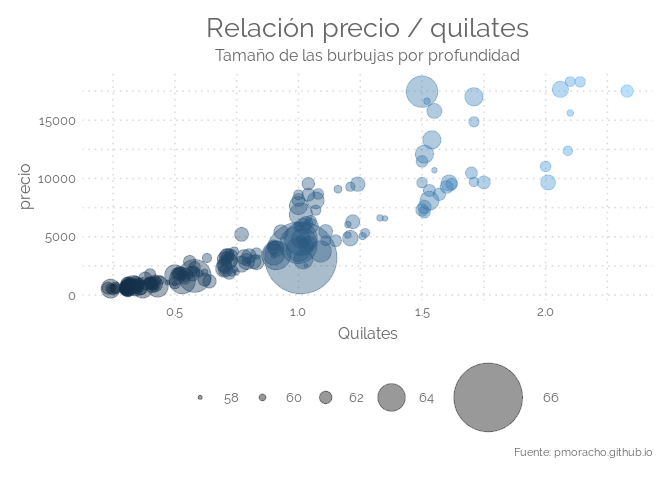
Bubble plot
Un gráfico de burbujas es un gráfico multivariable que es un cruce entre un gráfico de dispersión y un gráfico de área proporcional. Al igual que una gráfica de dispersión, los gráficos de burbujas utilizan un sistema de coordenadas cartesianas para trazar puntos a lo largo de una cuadrícula donde los ejes X e Y son variables separadas. Sin embargo, a diferencia de una gráfica de dispersión, a cada punto se le asigna una etiqueta o categoría (ya sea que se muestre al lado o en una leyenda). Cada punto trazado representa entonces una tercera variable por el área de su círculo. Los colores también pueden utilizarse para distinguir entre categorías o para representar una variable de datos adicional. El tiempo puede ser mostrado ya sea teniendo una variable en uno de los ejes o animando las variables de datos que cambian con el tiempo. Los gráficos de burbujas se utilizan normalmente para comparar y mostrar las relaciones entre los círculos categorizados, mediante el uso de la posición y las proporciones. La imagen general de los gráficos de burbujas se puede utilizar para analizar patrones/correlaciones. Demasiadas burbujas pueden hacer que el gráfico sea difícil de leer, por lo que los gráficos de burbujas tienen una capacidad limitada de tamaño de datos. Esto se puede remediar de alguna manera con la interactividad: haciendo clic o pasando el ratón por encima de las burbujas para mostrar información oculta, teniendo la opción de reorganizar o filtrar las categorías agrupadas. Al igual que con las Tablas de Área Proporcional, los tamaños de los círculos necesitan ser dibujados basados en el área del círculo, no en su radio o diámetro. No sólo el tamaño de los círculos cambiará exponencialmente, sino que esto llevará a interpretaciones erróneas por parte del sistema visual humano.
# Let's use the diamonds data set (available in base R)
data = diamonds %>% sample_n(200)
ggplot(data, aes(x=carat, y=price, size=depth, color=carat)) +
geom_point(alpha=0.4) +
scale_size_continuous( trans="exp", range=c(1, 25)) +
scale_colour_continuous(guide = FALSE) +
labs(title="Relación precio / quilates",
subtitle="Tamaño de las burbujas por profundidad",
caption="Fuente: pmoracho.github.io",
y="precio",
x="Quilates") +
theme_elegante()
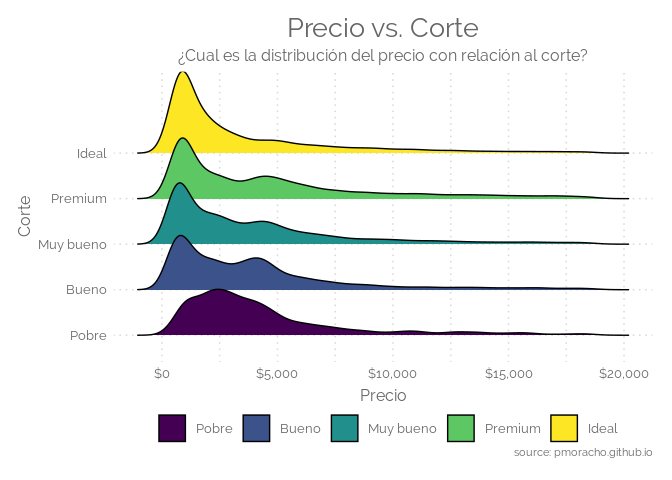
Ridgeline plot
Un gráfico Ridgeline o Joyplot muestra la distribución de un valor numérico para varios grupos. Pueden ser muy útiles para visualizar los cambios en las distribuciones a lo largo del tiempo o del espacio. La distribución puede representarse mediante histogramas o gráficos de densidad, todos alineados a la misma escala horizontal y presentados con un ligero solapamiento. Las gráficas son especialmente interesantes cuando el número de grupos a representar es alto y, por lo tanto, una separación clásica de ventanas requeriría de mucho más espacio. Sin embargo, hay que tener cuidado, ya que está gráfica suele ocultar una parte de los datos, donde se produce el solapamiento. En R, los gráficos de Ridgeline se pueden hacer fácilmente gracias a la librería ggridges de Claus Wilke, que es una extensión de ggplot2.
source: https://www.r-graph-gallery.com/ridgeline-plot/
library(ggridges)
library(ggplot2)
data("diamonds")
levels(diamonds$cut) <- c("Pobre", "Bueno", "Muy bueno", "Premium", "Ideal")
# basic example
ggplot(diamonds, aes(x = price, y = cut, fill = cut)) +
geom_density_ridges() +
labs(title = "Precio vs. Corte",
subtitle = "¿Cual es la distribución del precio con relación al corte?",
x = "Precio",
y = "Corte",
caption = "source: pmoracho.github.io" ) +
scale_x_continuous(labels=dollar_format(prefix="$")) +
scale_color_manual(values=c('#25AAE2','#F2B53A', '#8BC540', '#DC5D42', '#666666',
'9FAFBE')) +
theme_elegante()
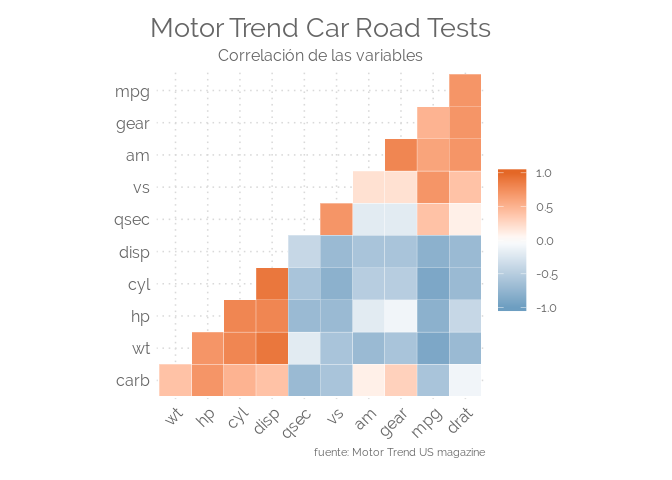
Correlograma
Un correlograma o matriz de correlación permite analizar la relación entre cada par de variables numéricas de una matriz. La correlación entre cada par de variables se visualiza a través de una gráfica de dispersión, o un símbolo que representa la correlación (burbuja, línea, número…). La diagonal representa la distribución de cada variable, utilizando un histograma o un gráfico de densidad. Esta técnica es ampliamente utilizada para el análisis exploratorio ya que evita hacer cientos de gráficos para observar una matriz.
library(ggplot2)
library(ggcorrplot)
# Correlation matrix
data(mtcars)
corr <- round(cor(mtcars), 1)
ggcorrplot(corr, hc.order = TRUE, type = "lower",
outline.col = "white",
ggtheme = theme_elegante,
colors = c("#6D9EC1", "white", "#E46726")) +
labs(title="Motor Trend Car Road Tests",
subtitle="Correlación de las variables",
caption="fuente: Motor Trend US magazine",
color=NULL) +
theme(legend.position="right")
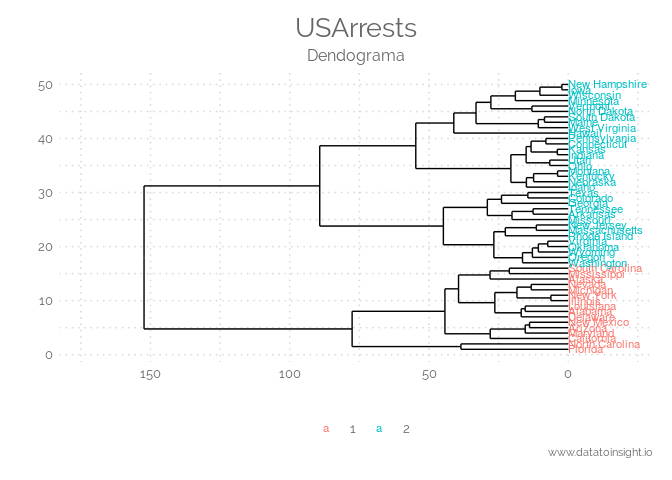
Dendograma
Un dendrograma es un tipo de representación gráfica o diagrama de datos en forma de árbol que organiza los datos en subcategorías que se van dividiendo en otros hasta llegar al nivel de detalle deseado (asemejándose a las ramas de un árbol que se van dividiendo en otras sucesivamente). Este tipo de representación permite apreciar claramente las relaciones de agrupación entre los datos e incluso entre grupos de ellos aunque no las relaciones de similitud o cercanía entre categorías. Observando las sucesivas subdivisiones podemos hacernos una idea sobre los criterios de agrupación de los mismos, la distancia entre los datos según las relaciones establecidas, etc. También podríamos referirnos al dendrograma como la ilustración de las agrupaciones derivadas de la aplicación de un algoritmo de clustering jerárquico.
jerárquico.
library(ggplot2)
library(ggdendro)
df <- USArrests # really bad idea to muck up internal datasets
hc <- hclust(dist(df), "ave") # heirarchal clustering
dendr <- dendro_data(hc, type="rectangle") # convert for ggplot
clust <- cutree(hc,k=2) # find 2 clusters
clust.df <- data.frame(label=names(clust), cluster=factor(clust))
# dendr[["labels"]] has the labels, merge with clust.df based on label column
dendr[["labels"]] <- merge(dendr[["labels"]],clust.df, by="label")
# plot the dendrogram; note use of color=cluster in geom_text(...)
ggplot() +
geom_segment(data=segment(dendr), aes(x=x, y=y, xend=xend, yend=yend)) +
geom_text(data=label(dendr), aes(x, y, label=label, hjust=0, color=cluster),
size=3) +
coord_flip() + scale_y_reverse(expand=c(0.2, 0)) +
theme(axis.line.y=element_blank(),
axis.ticks.y=element_blank(),
axis.text.y=element_blank(),
axis.title.y=element_blank(),
panel.background=element_rect(fill="white"),
panel.grid=element_blank()) +
labs(title = "USArrests",
subtitle = "Dendograma",
x = "",
y = "",
caption = "www.datatoinsight.io" ) +
theme_elegante()
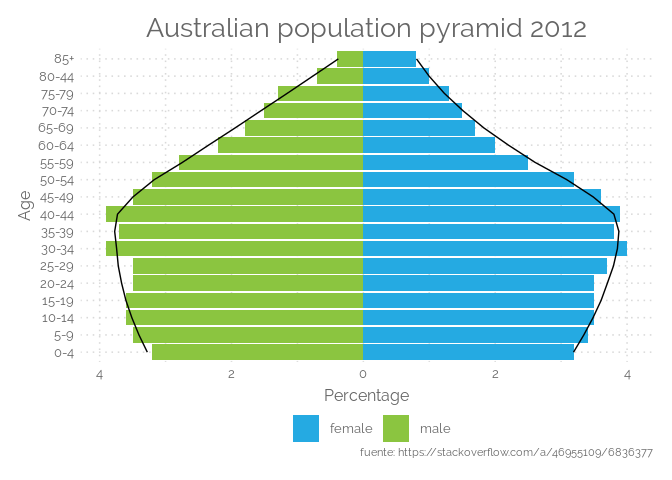
Population piramid
Conocida como una pirámide de edad y sexo. Una pirámide de población es un par de histogramas consecutivos (para cada sexo) que muestran la distribución de una población en todos los grupos de edad y en ambos sexos. El eje X se utiliza para trazar los números de población y el eje Y enumera todos los grupos de edad. Las pirámides de población son ideales para detectar cambios o diferencias en los patrones de población. Las pirámides de poblaciones múltiples pueden utilizarse para comparar patrones entre naciones o grupos de población seleccionados. La forma de una pirámide de población puede ser usada para interpretar una población. Por ejemplo, una pirámide con una base muy ancha y una sección superior estrecha sugiere una población con altas tasas de fertilidad y mortalidad. Mientras que una pirámide con una mitad superior más ancha y una base más estrecha sugeriría una población envejecida con bajas tasas de fertilidad. Las pirámides de población también pueden utilizarse para especular sobre el desarrollo futuro de una población. Una población que envejece y que no se está reproduciendo se encontraría con problemas como tener suficiente descendencia para cuidar a los ancianos. Otras teorías, como la de “Youth Bulge”, afirman que cuando hay un amplio bulto en el rango de edad de 16 a 30 años, particularmente en los hombres, esto conduce a disturbios sociales, guerra y terrorismo. Esto hace que las pirámides de población sean útiles para campos como la ecología, la sociología y la economía.
fuente: The Data Visualisation Catalogue
library(tidyverse)
# Your data
xy.pop<-c(3.2,3.5,3.6,3.6,3.5,3.5,3.9,3.7,3.9,3.5,3.2,2.8,2.2,1.8,1.5,1.3,0.7,0.4)
xx.pop<-c(3.2,3.4,3.5,3.5,3.5,3.7,4,3.8,3.9,3.6,3.2,2.5,2,1.7,1.5,1.3,1,0.8)
agelabels<-c("0-4","5-9","10-14","15-19","20-24","25-29","30-34",
"35-39","40-44","45-49","50-54","55-59","60-64","65-69","70-74",
"75-79","80-44","85+")
# Collect data in dataframe
df <- rbind.data.frame(
cbind.data.frame(Percentage = -xy.pop, Group = agelabels, Gender = "male"),
cbind.data.frame(Percentage = +xx.pop, Group = agelabels, Gender = "female")
);
# Make sure agelabels have the right order
df$Group <- factor(df$Group, levels = agelabels);
# (gg)plot
ggplot(data = df, aes(x = Group, y = Percentage, fill = Gender, group = Gender)) +
geom_bar(data = subset(df, Gender == "female"), stat = "identity") +
geom_bar(data = subset(df, Gender == "male"), stat = "identity") +
coord_flip() +
geom_smooth(colour = "black", method = "loess", se = FALSE, show.legend = FALSE, size = 0.5) +
scale_fill_manual(values=c('#25AAE2','#8BC540')) +
labs(
x = "Age",
y = "Percentage",
title = "Australian population pyramid 2012",
caption="fuente: https://stackoverflow.com/a/46955109/6836377") +
scale_y_continuous(
breaks = seq(-4, 4, by = 2),
labels = c(rev(seq(0, 4, by = 2)), seq(2, 4, by = 2))) +
theme_elegante()
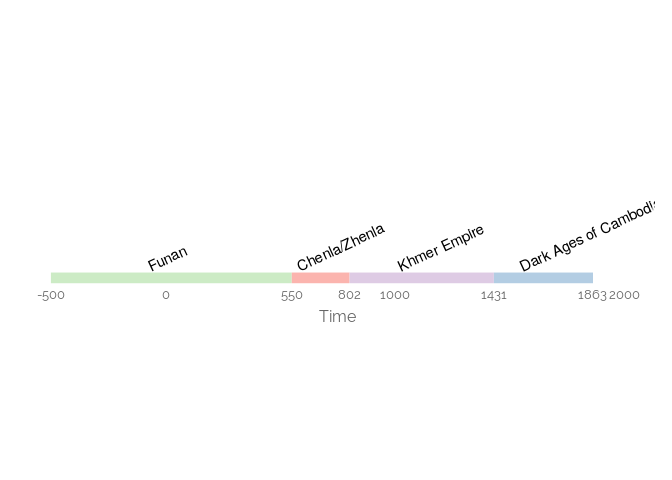
Timeline plot
Una línea de tiempo es una forma gráfica de mostrar una lista de eventos en orden cronológico. Algunas líneas de tiempo funcionan en una escala, mientras que otras simplemente muestran los eventos en secuencia. La función principal de Timelines es comunicar información relacionada con el tiempo, ya sea para el análisis o para presentar visualmente una historia o una visión de la historia. Si se basa en una escala, una línea de tiempo le permite ver cuándo ocurren o van a ocurrir las cosas, permitiendo al espectador evaluar los intervalos de tiempo entre los eventos. Esto permite al espectador ver cualquier patrón que aparezca en cualquier período de tiempo seleccionado o cómo se distribuyen los eventos en ese período de tiempo.
fuente: The Data Visualisation Catalogue
cambodia = data.frame(Period = c("Funan", "Chenla/Zhenla","Khmer Empire","Dark Ages of Cambodia"),StartDate = c(-500,550,802,1431), EndDate = c(550,802,1431,1863), Color = c("lightblue","lightgreen","lightyellow","pink"))
ggplot(data=cambodia) +
geom_segment(aes(x=StartDate, xend=EndDate, y=0., yend=0., color=Period) , linetype=1, size=4) +
scale_colour_brewer(palette = "Pastel1")+
scale_y_continuous(limits=c(0,0.5))+
scale_x_continuous(limits=c(-500,2000), breaks= c(seq(0,2000,by=1000), cambodia$StartDate, cambodia$EndDate[4]))+
xlab("Time")+
ylab("Periods of History")+
theme_elegante() +
theme(panel.grid.minor = element_blank(), panel.grid.major = element_blank(), axis.title.y=element_blank(),axis.text.y=element_blank(), axis.ticks.y=element_blank()) +
theme(aspect.ratio = .2)+
theme(legend.position="none") +
geom_text(aes(x=StartDate-100 + (EndDate- StartDate)/2,y=0.05,label=Period,angle=25,hjust=0))
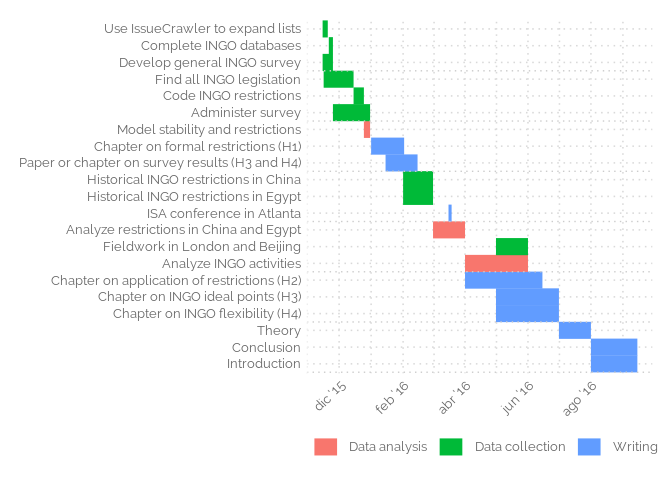
Gantt diagram
library(tidyverse)
library(lubridate)
library(scales)
library(Cairo)
# Alternatively you can put all this in a CSV file with the same columns and
# then load it with read_csv()
# tasks <- read_csv("path/to/the/file")
tasks <- tribble(
~Start, ~End, ~Project, ~Task,
"2015-11-15", "2015-11-20", "Data collection", "Use IssueCrawler to expand lists",
"2015-11-21", "2015-11-25", "Data collection", "Complete INGO databases",
"2015-11-16", "2015-12-15", "Data collection", "Find all INGO legislation",
"2015-12-15", "2015-12-25", "Data collection", "Code INGO restrictions",
"2015-11-15", "2015-11-25", "Data collection", "Develop general INGO survey",
"2015-11-25", "2015-12-31", "Data collection", "Administer survey",
"2015-12-25", "2015-12-31", "Data analysis", "Model stability and restrictions",
"2016-01-01", "2016-02-02", "Writing", "Chapter on formal restrictions (H1)",
"2016-01-15", "2016-02-15", "Writing", "Paper or chapter on survey results (H3 and H4)",
"2016-03-16", "2016-03-19", "Writing", "ISA conference in Atlanta",
"2016-02-01", "2016-03-01", "Data collection", "Historical INGO restrictions in China",
"2016-02-01", "2016-03-01", "Data collection", "Historical INGO restrictions in Egypt",
"2016-05-01", "2016-06-01", "Data collection", "Fieldwork in London and Beijing",
"2016-03-01", "2016-04-01", "Data analysis", "Analyze restrictions in China and Egypt",
"2016-04-01", "2016-06-01", "Data analysis", "Analyze INGO activities",
"2016-04-01", "2016-06-15", "Writing", "Chapter on application of restrictions (H2)",
"2016-05-01", "2016-07-01", "Writing", "Chapter on INGO ideal points (H3)",
"2016-05-01", "2016-07-01", "Writing", "Chapter on INGO flexibility (H4)",
"2016-07-01", "2016-08-01", "Writing", "Theory",
"2016-08-01", "2016-09-15", "Writing", "Conclusion",
"2016-08-01", "2016-09-15", "Writing", "Introduction"
)
# Convert data to long for ggplot
tasks.long <- tasks %>%
mutate(Start = ymd(Start),
End = ymd(End)) %>%
gather(date.type, task.date, -c(Project, Task)) %>%
arrange(date.type, task.date) %>%
mutate(Task = factor(Task, levels=rev(unique(Task)), ordered=TRUE))
# Calculate where to put the dotted lines that show up every three entries
x.breaks <- seq(length(tasks$Task) + 0.5 - 3, 0, by=-3)
# Build plot
ggplot(tasks.long, aes(x=Task, y=task.date, colour=Project)) +
geom_line(size=6) +
geom_vline(xintercept=x.breaks, colour="grey80", linetype="dotted") +
guides(colour=guide_legend(title=NULL)) +
labs(x=NULL, y=NULL) + coord_flip() +
scale_y_date(date_breaks="2 months", labels=date_format("%b ‘%y")) +
theme_elegante() +
theme(axis.text.x=element_text(angle=45, hjust=1))