Patrones de desbloqueo de Android
7 Jul 2021 31 minsIntroducción
Cuando me aburro, me pueden encontrar respondiendo preguntas en stackoverflow o haciendo desafíos en codewars. De este último es el interesante problema: Screen Locking Patterns. La idea es bien simple, dado un punto inicial en el patrón de bloqueo de Android, un cuadrado de 3x 3, y un número de puntos, calcular la cantidad de posibles patrones. Por supuesto:
- Los patrones deben ser válidos
- Longitudes de 0 o de más de 10 o más puntos tienen que arrojar como resultado 0
Y ¿qué es un patrón válido?
- Los puntos no deben repetirse
- Se va de un punto a otro sin pasar por encima de un tercero, a menos que:
- Por el tercer punto ya se haya pasado. Por ejemplo
A -> Ces un movimiento inválido, por que en el medio del movimiento se pasa por encima deB, sin embargo, es totalmente válido hacerB -> A -> C
Hay otra restricción no escrita, la solución debe poder correr en un tiempo razonable. ¿Cuán razonable? lo determina el servidor de codewars.
¿Cómo resolverlo?
Esta fue la primer pregunta que me hice, ciertamente parece un problema para aplicar algún algoritmo de camino o incluso de árboles, pero como soy cómodo, elegí la opción fácil: “fuerza bruta”, pero entonces ¿podemos calcular previamente todos los caminos posibles y enfocarnos luego a encontrar los que son válidos descartando aquellos que no lo son?. Veamos, tenemos un patrón de 3 x 3, con puntos que no deben repetirse, por lo que en definitiva hay un espacio de posibilidades de respuesta, que seguro no es mayor a las permutaciones de los 9 puntos sin repeticiones por las 9 posibles longitudes pedidas:
factorial(9) * 9
## [1] 3265920
O sea 3.26592^{6}, un número importante sin duda, pero no imposible de manejar. Lógicamente no todas estas combinaciones son válidas, pero eso, por ahora es otro problema.
NOTA: Como siempre, de acá a un par de días seguramente ya no me acuerde que son las permutaciones, bueno, si tenemos 9 elementos distintos, las permutaciones sin repetición son todas las formas en que se pueden ordenar estos.
Permutaciones en R
Ya vimos que el número a manejar es importante pero razonable, ahora bien ¿Cómo podemos generar todas las permutaciones de 9 elementos en R? Bueno, algo sorprendido, debo decir que no hay ninguna rutina “base” para generar esto, tampoco es que sea nada del otro mundo, con un simple código recursivo lo podemos realizar, pero en la red la mayoría de la recomendaciones pasan por usar paquetes adicionales, tales como:
También hay algunas funciones de permutación interesantes para mantener el código simple y no recurrir a paquetes adicionales. no lo probé, pero dudo que codewars permita instalar paquetes de terceros:
- Learning R: Permutations and Combinations with base R
- Generating all distinct permutations of a list in R
Veamos una recopilación de funciones interesantes y estudiemos su performance con microbenchmark:
# From: https://www.r-bloggers.com/2019/06/learning-r-permutations-and-combinations-with-base-r/
permutate_1 <- function(v) {
n <- length(v)
if (n == 1) v
else {
X <- NULL
for (i in 1:n) X <- rbind(X, cbind(v[i], permutate_1(v[-i])))
X
}
}
# From: https://stackoverflow.com/a/20199902/6836377
permutate_2 <- function(values) {
permutations <- function(n){
if(n==1){
return(matrix(1))
} else {
sp <- permutations(n-1)
p <- nrow(sp)
A <- matrix(nrow=n*p,ncol=n)
for(i in 1:n){
A[(i-1)*p+1:p,] <- cbind(i,sp+(sp>=i))
}
return(A)
}
}
n <- length(values)
matrix(values[permutations(n)], ncol=n)
}
# From: https://stackoverflow.com/a/20199902/6836377
permutate_3 <- function(x){
stopifnot(is.atomic(x)) # for the matrix call to make sense
out <- as.matrix(expand.grid(
replicate(length(x), x, simplify = FALSE), stringsAsFactors = FALSE))
out[apply(out,1, anyDuplicated) == 0, ]
}
# From: https://stackoverflow.com/a/65354641/6836377
permutate_4 <- function(x, prefix = c()){
if(length(x) == 1) # was zero before
return(list(c(prefix, x)))
out <- do.call(c, lapply(1:length(x), function(idx)
permutate_4(x[-idx], c(prefix, x[idx]))))
if(length(prefix) > 0L)
return(out)
do.call(rbind, out)
}
# From: https://stackoverflow.com/a/34287541/6836377
permutate_5 <- function(x) {
if (length(x) == 1) {
return(x)
}
else {
res <- matrix(nrow = 0, ncol = length(x))
for (i in seq_along(x)) {
res <- rbind(res, cbind(x[i], Recall(x[-i])))
}
return(res)
}
}
casos <- LETTERS[1:6]
microbenchmark::microbenchmark(permutate_1 = permutate_1(casos),
permutate_2 = permutate_2(casos),
permutate_3 = permutate_3(casos),
permutate_4 = permutate_4(casos),
permutate_5 = permutate_5(casos), times = 10) -> df
Resultado:
summary(df)
## expr min lq mean median uq max
## 1 permutate_1 4065.715 4399.902 5624.935 5041.505 5467.740 12553.52
## 2 permutate_2 190.860 207.353 1474.130 236.006 256.725 12669.85
## 3 permutate_3 155386.740 158331.697 170237.758 165408.234 177839.048 211614.81
## 4 permutate_4 4367.584 4714.645 6545.433 5317.123 5883.764 12588.24
## 5 permutate_5 5439.218 5612.255 7676.531 6077.719 10172.385 13263.32
## neval
## 1 10
## 2 10
## 3 10
## 4 10
## 5 10
Visualmente:
df %>%
ggplot(df, mapping=aes(y=expr, x=time, fill=expr)) +
geom_violin() +
theme_elegante_std() +
scale_x_log10(
breaks = scales::trans_breaks("log10", function(x) 10^x),
labels = scales::trans_format("log10", scales::math_format(10^.x))
) +
labs(title = paste("Performance"),
subtitle = paste("de varias rutinas de permutación") ,
caption = "",
y = "",
x = "microsegundos"
)
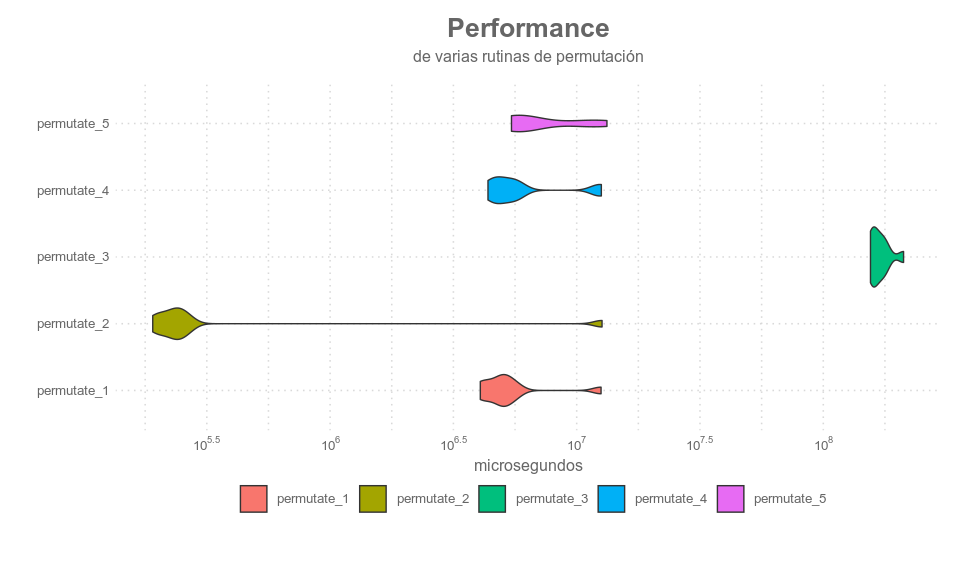
La rutina dos, sin duda se lleva todos los premios, aunque parece tener una larga cola producto de un “outlier”, algo curioso, ya que si bien tiene un funcionamiento bastante estable, se verifica siempre que la segunda ejecución es dónde el tiempo crece hasta 5 veces el valor medio.
library(tidyverse)
df %>%
as.data.frame() %>%
filter(expr == 'permutate_2')
## expr time
## 1 permutate_2 269532
## 2 permutate_2 12669850
## 3 permutate_2 226465
## 4 permutate_2 256725
## 5 permutate_2 238852
## 6 permutate_2 190860
## 7 permutate_2 200507
## 8 permutate_2 247994
## 9 permutate_2 233160
## 10 permutate_2 207353
Pero más allá de esta cuestión anectdotica, la rutina de museful parece ser la que mejores resultados ofrece en cuanto a tiempo.
Ya tenemos una forma de generar todas las permutaciones de los 9 puntos:
permutate <- function(values) {
permutations <- function(n){
if(n==1){
return(matrix(1))
} else {
sp <- permutations(n-1)
p <- nrow(sp)
A <- matrix(nrow=n*p,ncol=n)
for(i in 1:n){
A[(i-1)*p+1:p,] <- cbind(i,sp+(sp>=i))
}
return(A)
}
}
n <- length(values)
matrix(values[permutations(n)], ncol=n)
}
M <- permutate(LETTERS[1:9])
head(M)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] "A" "B" "C" "D" "E" "F" "G" "H" "I"
## [2,] "A" "B" "C" "D" "E" "F" "G" "I" "H"
## [3,] "A" "B" "C" "D" "E" "F" "H" "G" "I"
## [4,] "A" "B" "C" "D" "E" "F" "H" "I" "G"
## [5,] "A" "B" "C" "D" "E" "F" "I" "G" "H"
## [6,] "A" "B" "C" "D" "E" "F" "I" "H" "G"
length(M)
## [1] 3265920
Una de las restricciones, que se nos pide, es una longitud o cantidad de puntos, por lo que deberemos “recortar” la matriz en función de dicha longitud, el problema es que al hacer esto, quedaran permutaciones repetidas que tendremos que eliminar. La otra restricción es que se nos pide comenzar de un determinado punto, por lo que deberemos filtrar nuestra matriz por el valor de la primer columna. Imaginemos que se nos pide comenzar el patrón desde el punto D y que la longitud sea 3:
l <- 3
f <- "D"
todos <- apply(unique(M[M[,1] == f, 1:l]), 1, paste, collapse="")
todos
## [1] "DAB" "DAC" "DAE" "DAF" "DAG" "DAH" "DAI" "DBA" "DBC" "DBE" "DBF" "DBG"
## [13] "DBH" "DBI" "DCA" "DCB" "DCE" "DCF" "DCG" "DCH" "DCI" "DEA" "DEB" "DEC"
## [25] "DEF" "DEG" "DEH" "DEI" "DFA" "DFB" "DFC" "DFE" "DFG" "DFH" "DFI" "DGA"
## [37] "DGB" "DGC" "DGE" "DGF" "DGH" "DGI" "DHA" "DHB" "DHC" "DHE" "DHF" "DHG"
## [49] "DHI" "DIA" "DIB" "DIC" "DIE" "DIF" "DIG" "DIH"
Hemos logrado obtener todas las combinaciones comenzando en D y con una longitud 3 de los 9 posibles puntos. El problema final, es que no todas estas combinaciones son válidas. Ya habíamos comentado, que no se puede saltear un punto, por ejemplo D -> F es una combinación inválida por que en el medio está E igual ocurre con F -> D sin embargo, y acá está lo complejo, podría ser válido hacer E -> D -> F en este caso el conjunto D -> F es válido por que ya hemos pasado por E. Hay una resolución muy interesante en Python aqui que calcula la cantidad de soluciones totales, y maneja un diccionario dónde se guardan los movimientos inválidos y el punto para que eventualmente dicho patrón sea válido, en R sería algo como esto:
invalidos <- read.table(text='patron, a_menos_que
"AC", "B"
"AI", "E"
"AG", "D"
"BH", "E"
"CA", "B"
"CG", "E"
"CI", "F"
"DF", "E"
"FD", "E"
"GA", "D"
"GI", "H"
"GC", "E"
"HB", "E"
"IG", "H"
"IC", "F"
"IA", "E"', header=TRUE, sep=",", strip.white=TRUE, stringsAsFactors = FALSE)
Es decir, tenemos un data.frame con los movimientos inválidos y una columna a_menos_que que nos dice, para dicho patrón, el punto que debería existir antes para considerarlo válido.
Teniendo esto y las permutaciones arrancando de un punto dado y de la longitud solicitada, lo único que restaría es eliminar efectivamente los patrones inválidos. Imagino que hay varias formas de hacerlo, yo elegí usar expresiones regulares, armando un patrón regex a partir de invalidos dónde encontrar aquellos efectivamente inválidos, es decir que no tengan un a_menos_que antes:
patrones <- paste(apply(invalidos, 1, function(x) {paste0("^[^", x[2], "]*", x[1], ".*$|", x[1], ".*", x[2])}), collapse="|")
patrones
## [1] "^[^B]*AC.*$|AC.*B|^[^E]*AI.*$|AI.*E|^[^D]*AG.*$|AG.*D|^[^E]*BH.*$|BH.*E|^[^B]*CA.*$|CA.*B|^[^E]*CG.*$|CG.*E|^[^F]*CI.*$|CI.*F|^[^E]*DF.*$|DF.*E|^[^E]*FD.*$|FD.*E|^[^D]*GA.*$|GA.*D|^[^H]*GI.*$|GI.*H|^[^E]*GC.*$|GC.*E|^[^E]*HB.*$|HB.*E|^[^H]*IG.*$|IG.*H|^[^F]*IC.*$|IC.*F|^[^E]*IA.*$|IA.*E"
found_invalid <- sapply(gregexpr(patrones,todos), `[[`, 1) > -1
todos[!found_invalid]
## [1] "DAB" "DAE" "DAF" "DAG" "DAH" "DBA" "DBC" "DBE" "DBF" "DBG" "DBI" "DCB"
## [13] "DCE" "DCF" "DCH" "DEA" "DEB" "DEC" "DEF" "DEG" "DEH" "DEI" "DGA" "DGB"
## [25] "DGE" "DGF" "DGH" "DHA" "DHC" "DHE" "DHF" "DHG" "DHI" "DIB" "DIE" "DIF"
## [37] "DIH"
n <- length(todos[!found_invalid])
n
## [1] 37
Implementamos todo esto en una función, agregamos lógica para los caminos inferiores a 1 o superiores a 9, y un “truquito” para evitar el calculo cuando la longitud es 1.
count_patterns_from <- function(f, l) {
if (l >= 10 | l <= 0) return(0)
if (l == 1) return(1)
invalidos <- read.table(text='patron, a_menos_que
"AC", "B"
"AI", "E"
"AG", "D"
"BH", "E"
"CA", "B"
"CG", "E"
"CI", "F"
"DF", "E"
"FD", "E"
"GA", "D"
"GI", "H"
"GC", "E"
"HB", "E"
"IG", "H"
"IC", "F"
"IA", "E"', header=TRUE, sep=",", strip.white=TRUE, stringsAsFactors = FALSE)
permutate <- function(values) {
permutations <- function(n){
if(n==1){
return(matrix(1))
} else {
sp <- permutations(n-1)
p <- nrow(sp)
A <- matrix(nrow=n*p,ncol=n)
for(i in 1:n){
A[(i-1)*p+1:p,] <- cbind(i,sp+(sp>=i))
}
return(A)
}
}
n <- length(values)
matrix(values[permutations(n)], ncol=n)
}
M <- permutate(LETTERS[1:9])
todos <- apply(unique(M[M[,1] == f, 1:l]), 1, paste, collapse="")
patrones <- paste(apply(invalidos, 1, function(x) {paste0("^[^", x[2], "]*", x[1], ".*$|", x[1], ".*", x[2])}), collapse="|")
found_invalid <- sapply(gregexpr(patrones,todos), `[[`, 1) > -1
n <- length(todos[!found_invalid])
n
#list(n, todos, patrones, found_invalid)
}
Y ya tenemos la función solicitada en el desafío. Un momento: ¿seguro?, bueno en realidad no, si bien funciona bien y con un tiempo de calculo razonable, lamentablemente no tan “razonable” para codewars. Qué desepción! tanto trabajo para nada, a menos que… no no puede funcionar.. aparte sería una vergüenza.. bueno al menos podríamos probarlo. ¿Y sí precalculamos el espacio de solución? a ver.. tenemos 9 letras y 9 posibles longitudes, o sea 81 posibilidades
generate_all <- function() {
t <- data.frame(expand.grid(LETTERS[1:9], 1:9))
cnt <- c()
for (v in 1:nrow(t)){
cnt <- c(cnt, count_patterns_from(t[v,1], t[v,2]))
}
cnt
}
M <- generate_all()
M
## [1] 1 1 1 1 1 1 1 1 1 5 7 5
## [13] 7 8 7 5 7 5 31 37 31 37 48 37
## [25] 31 37 31 154 188 154 188 256 188 154 188 154
## [37] 684 816 684 816 1152 816 684 816 684 2516 2926 2516
## [49] 2926 4248 2926 2516 2926 2516 7104 8118 7104 8118 12024 8118
## [61] 7104 8118 7104 13792 15564 13792 15564 23280 15564 13792 15564 13792
## [73] 13792 15564 13792 15564 23280 15564 13792 15564 13792
Con la anterior matriz bien podemos hacer algo así:
count_patterns_from <- function(f, l) {
if (l > 9| l <= 0) return(0)
m <- structure(c(1, 1, 1, 1, 1, 1, 1, 1, 1, 5, 7, 5, 7, 8, 7, 5, 7,
5, 31, 37, 31, 37, 48, 37, 31, 37, 31, 154, 188, 154, 188, 256,
188, 154, 188, 154, 684, 816, 684, 816, 1152, 816, 684, 816,
684, 2516, 2926, 2516, 2926, 4248, 2926, 2516, 2926, 2516, 7104,
8118, 7104, 8118, 12024, 8118, 7104, 8118, 7104, 13792, 15564,
13792, 15564, 23280, 15564, 13792, 15564, 13792, 13792, 15564,
13792, 15564, 23280, 15564, 13792, 15564, 13792), .Dim = c(9L,
9L), .Dimnames = list(c("A", "B", "C", "D", "E", "F", "G", "H",
"I"), c("1", "2", "3", "4", "5", "6", "7", "8", "9")))
m[f, l]
}
Y funcionó! pareciera un poco tramposo, pero es totalmente válido, tenemos una función que resuelve la totalidad del problema, técnicamente, no tiene lógica, solo una matriz de soluciones, después de todo fue legítimo el esfuerzo para construir la matriz (vamos, que seguramente la podría haber copiado y pegado de algún lado). Igualmente, revisando las soluciones de otros usuarios, me encontré que muchos optaron por hacer lo mismo:
# From https://www.codewars.com/users/elmstedt
count_patterns_from_1 <- function(f, l) {
# Cheating Solution
if (l < 1 || l > 9) return(0)
ac <- structure(c(1, 1, 1, 1, 1, 1, 1, 1, 1,
5, 7, 5, 7, 8, 7, 5, 7, 5,
31, 37, 31, 37, 48, 37, 31, 37, 31,
154, 188, 154, 188, 256, 188, 154, 188, 154,
684, 816, 684, 816, 1152, 816, 684, 816, 684,
2516, 2926, 2516, 2926, 4248, 2926, 2516, 2926, 2516,
7104, 8118, 7104, 8118, 12024, 8118, 7104, 8118, 7104,
13792, 15564, 13792, 15564, 23280, 15564, 13792, 15564, 13792,
13792, 15564, 13792, 15564, 23280, 15564, 13792, 15564, 13792),
.Dim = c(9, 9))
ac[match(f, LETTERS), l]
}
# From https://www.codewars.com/users/Schleiffer
count_patterns_from_2 <- function(f, l) {
if (l<1 | l>9) return(0)
res<-c(1, 5, 31, 154, 684, 2516, 7104, 13792, 13792, 1, 7, 37, 188, 816, 2926, 8118, 15564, 15564, 1, 8, 48, 256, 1152, 4248, 12024, 23280, 23280)
sel<-0 + 1 * (f %in% c("B","D","F","H")) + 2 * (f == "E")
return(res[l+sel*9])
}
# user8436785
count_patterns_from_3<- function(f, l) if (l > 9) 0 else if (l < 2) l else c(C2 = 5, C3 = 31, C4 = 154, C5 = 684, C6 = 2516, C7 = 7104, C8 = 13792, C9 = 13792, S2 = 7, S3 = 37, S4 = 188, S5 = 816, S6 = 2926, S7 = 8118, S8 = 15564, S9 = 15564, M2 = 8, M3 = 48, M4 = 256, M5 = 1152, M6 = 4248, M7 = 12024, M8 = 23280, M9 = 23280)[[paste0(if (f == 'E') 'M' else if (grepl(f, 'ACGI', fixed=TRUE)) "C" else "S", l)]]
¿Y como se comportan estas funciones precalculadas?
Midamos los tiempos:
microbenchmark::microbenchmark(count_patterns_from = count_patterns_from("E", 9),
count_patterns_from_1 = count_patterns_from_1("E", 9),
count_patterns_from_2 = count_patterns_from_2("E", 9),
count_patterns_from_3 = count_patterns_from_3("E", 9), times = 10) -> df
summary(df)
## expr min lq mean median uq max neval
## 1 count_patterns_from 10.729 11.736 592.3144 13.5375 15.871 5796.512 10
## 2 count_patterns_from_1 8.828 9.656 637.8339 10.4460 14.651 6266.660 10
## 3 count_patterns_from_2 3.193 4.183 747.3586 4.7925 8.414 7422.810 10
## 4 count_patterns_from_3 6.916 7.313 459.2330 8.1025 10.659 4508.255 10
Visualmente:
df %>%
ggplot(df, mapping=aes(y=expr, x=time, fill=expr)) +
geom_violin() +
theme_elegante_std() +
scale_x_log10(
breaks = scales::trans_breaks("log10", function(x) 10^x),
labels = scales::trans_format("log10", scales::math_format(10^.x))
) +
labs(title = paste("Performance"),
subtitle = paste("de las rutinas precalculadas") ,
caption = "",
y = "",
x = "microsegundos"
)
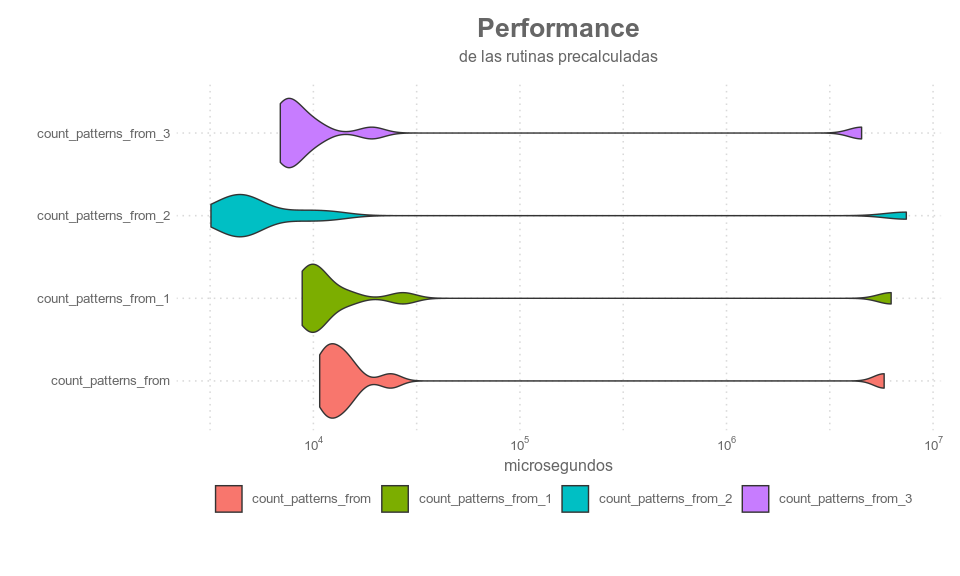
Como era de esperar se comportan bastante parecido todas. ¿Y las otras? hay varias soluciones no precalculads que me intrigan ver como funcionan. (Veremos… TO BE CONTINUED)
Lecciones aprendidas
- Hacer una función precalculada, no es una deshonra al gremio de los programadores, es más, posiblemente sea la que menos “bugs” pueda llegar a tener eventualmente.
- Una obviedad, la fuerza “bruta” sirve, siempre que el espacio de solución sea acotado a los limites que impone el hardware
- Las expresiones regulares sirven para casi todo.